Построение формальной модели
Построение формальной модели
Изложенные положения модели дают основания перейти к ее формализации[7]. Эта формализация имеет двоякое значение. Во-первых, в практическом плане она открывает путь к количественным оценкам и тем самым сообщает модели предсказательные возможности. В частности, она позволяет дать экономические оценки различным сценариям работы с одаренными детьми. Во-вторых, в исследовательском плане формализация ускоряет процесс совершенствования теории, поскольку позволяет формулировать точные предсказания, соотнесение которых с действительностью выявляет нестыковки в теории и заставляет вносить в последнюю изменения. В то же время любая формализация связана со схематизацией, отбрасыванием части «пышно зеленеющего древа жизни» в пользу сухой теории. В особой степени это касается ее начальных этапов, когда закладываются принципы схематизации для той или иной области. Поэтому представляется, что оптимальным путем сегодня является сочетание двух подходов – номотетического, стремящегося к созданию абстрактных моделей, и идеографического, сохраняющего богатство живого представления о человеческой личности.
Вначале необходимо ввести функции, отображающие способности на компетентности и компетентности – на экономические достижения. Первая описывает, каким образом у групп людей, включенных в экономический процесс, на основе способностей формируются компетентности, и фактически является показателем работы образовательной системы страны. Функция, отображающая компетентности на экономические достижения, характеризует экономическую систему государства, а именно востребованность в ней высококомпетентных специалистов.
Для наших целей удобно сразу использовать одну функцию, являющуюся композицией двух перечисленных, поскольку при этом можно воспользоваться данными Р. Линна, которые приводят в соответствие способности и экономические достижения.
Для удобства последующих расчетов преобразуем оси интеллекта I и экономических показателей D таким образом, чтобы все данные Линна уместились в отрезках [0, 1]. Это достигается за счет следующего преобразования:
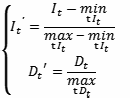
где индекс t обозначает соответствующую страну в данных Линна. Далее будем работать в новых осях, поэтому штрихи учитывать для удобства не будем.
Рассмотрим два варианта аппроксимации: при помощи степенной функции и при помощи показательной функции, которую предлагает Дикерсон (Dickerson, 2006). Мы пойдем по двум путям отдельно, а потом сравним полученные результаты.
Все степенные и показательные функции представим в виде трехпараметрического семейства:
F1(I; k, m, a) = m(I – a)k,
F2(I; k, m, a) = m ? k(I – a).
Будем искать соответствующие функции f1(I) и f2(I) методом наименьших квадратов:
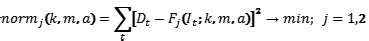
Следует отметить, что данные Линна имеют различную надежность для разных стран. Для большей части стран они основываются на эмпирических исследованиях, охвативших выборки большего или меньшего размера. Однако Линн расширяет свой список путем добавления стран, для которых интеллект оценен косвенно, в частности, путем сопоставления с интеллектом в соседних странах. Таким образом, мы располагаем менее обширным списком стран, для которых оценки интеллекта более надежны, и расширенным списком, для которого, однако, оценки интеллекта менее надежны. Расчеты были проведены отдельно по полному списку и – по сокращенному. В последний были включены страны, где данные по интеллекту были получены на выборке не менее 400 человек.
Линн сопоставляет свои данные по интеллекту с показателями ВВП за 2002 г. Более на дежно, однако, брать данные по ВВП не за один год, а за несколько, поскольку этим снижается влияние краткосрочных экономических факторов. Соответственно мы осуществили расчеты как на основании приводимых Линном данных за 2002 г., так и на основании усредненных показателей за 2002, 2006 и 2007 гг. Данные за 2006 г. были взяты с сайта Международной организации здравоохранения (World Health Organization), а за 2007 г. – с сайта Всемирного банка (World Bank). Данные за 2006 и 2007 гг. удалось получить не по всем странам, представленным в списках Линна, поэтому краткий список сократился на 6 стран, а расширенный – на 10. Из всех выборок исключены Китай и Экваториальная Гвинея.
Результат решения задачи для разных вариантов данных суммирует таблица 1.4.
На основании данных, представленных в таблице, можно заключить, что наиболее точно связь национального интеллекта и доходов на душу населения аппроксимирует степенная функция с показателями, варьируемыми от 2,08 до 2,6 для разных вариантов данных. Однако если взять показатель степени, равный 2, то полученная квадратичная функция, как видно из таблицы 1.4, аппроксимирует данные лишь чуть хуже, чем степенная с оптимально определенным показателем степени, и примерно так же (а для данных с достоверными коэффициентами интеллекта даже лучше), как это делает показательная функция. Стоит отметить, что точность аппроксимации в случае усредненных доходов на душу населения по трем годам оказывается выше, чем для одного года.
Далее мы проведем расчеты на основании двух моделей – квадратичной и степенной, а затем сравним сходство вытекающих из них оценок. Эти модели являются наиболее контрастными, поскольку степенная предполагает наиболее быстрый рост функции при возрастании аргумента, а квадратичная – наиболее медленный. Следовательно, степенная модель будет давать наиболее высокие оценки экономическому вкладу одаренной части населения, а квадратичная – самые низкие. В связи с этим, если оценки, полученные на основании двух моделей, окажутся достаточно близкими, это станет свидетельством высокой стабильности результатов, получаемых на основании предложенного подхода.
Таблица 1.4. Аппроксимация связи национального интеллекта и доходов на душу населения
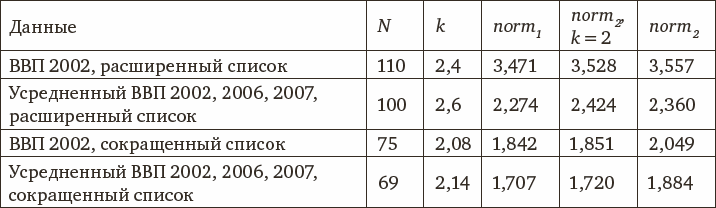
Примечание: N – количество стран, k – полученный в результате решения задачи коэффициент степенной функции. В остальных трех столбцах отображены полученные нормы соответственно для степенной модели, для степенной модели с заданной степенью равной 2 и для показательной модели.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Построение социальных файрволов
Построение социальных файрволов В этом разделе мы снова поговорим о том, как не допустить того, чтобы ваша организация стала добычей социальных инженеров и социальных хакеров. Чтобы избежать повторов, мы не будем здесь приводить различные рекомендации на эту же тему,
Построение фигур из 8-10 карточек
Построение фигур из 8-10 карточек Во всех заданиях этого раздела ребенку дают образец и карточки по типу «плоскостного Кооса».Задание 1. «Конфета-карамель». «Ты узнал, на что похожа эта фигура? Да, действительно, она похожа на конфету. Сколько карточек тебе нужно для этой
Раздел 4.3. Условия формальной правильности для оценки новых идей
Раздел 4.3. Условия формальной правильности для оценки новых идей (Tools for Dreamers, pp. 60–62)Критерии, используемые для тестовой фазы каждой стадии креативного процесса, в общих чертах соответствуют тому, что в НЛП носит название «условия формальной правильности». Эти условия
Построение мостика
Построение мостика Чем больше узнаешь о богатстве образов и разнообразии субъективных смыслов, тем более очевидной становится ограниченность психологии, объясняющей поведение человека по принципу стимул-реакция (S-R). Приверженцы теории S-R полагают, что, зная, каков
Экология: построение альтернативы
Экология: построение альтернативы Мне было приятно отметить, что большинство из вас сделали очень много для проверки на экологичность. Вы открыли, что иногда людям необходимо кое-что отрегулировать перед переходом через порог. В прошлом году один курильщик пытался
Психологические ключи: от модели ROLE к модели BAGEL
Психологические ключи: от модели ROLE к модели BAGEL Элементы модели ROLE сосредоточены главным образом на когнитивных процессах. Однако для реального функционирования данным ментальным программам необходимо определенное телесное и психическое воплощение. Физические
Глава 4: Построение отношений.
Глава 4: Построение отношений. — Я всегда думал, что отношения, завязанные в экстремальных ситуациях непродолжительны. — Придется завязать их на сексе. — Как скажете, мэм, «Скорость» (фильм). Что же дальше? Дальше мы всё совместим, чтобы получить окончательное понимание,
Построение системы
Построение системы Как только вас назначают руководителем совершенно нового подразделения или вы как предприниматель основываете новую фирму, вы сразу должны построить систему. В случае с людьми ваши действия состоят из двух этапов.1. Вы должны прописать
Как менять модели мышления и как создавать свои собственные модели?
Как менять модели мышления и как создавать свои собственные модели? Шаг первый.Самый первый шаг в любом начинании – это знать, что ты хочешь!!!Это самый главный и самый важный шаг, потому что именно он определяет вектор твоего развития. Сейчас я читаю книгу Арнольда
3. Построение лекции
3. Построение лекции Достоинство всякой лекции в немалой степени зависит от её построения. К работе над построением лекции приступают после того, как материал для неё в основном отобран и изучен.КомпозицияПод композицией лекции понимают сочетание её частей, то — есть
Построение взаимоотношений
Построение взаимоотношений Мы все прекрасно знаем, что на нашу просьбу могут ответить отказом.Например, кому-то может не понравиться ваша смелость. Или человек, у которого вы что-либо попросили, оценит риски и усомнится в своей выгоде.Кроме того, если ваши отношения с
Построение себя
Построение себя Знание семейной системыБез проведения работы по выявлению функциональных характеристик и исторических фактов, касающихся жизни своей расширенной семьи на протяжении многих поколений и своей собственной жизни, человек не сможет достичь эмоционального