«Рядовые лидеры» на Twitter
«Рядовые лидеры» на Twitter
Как тут же было подмечено, этот вывод целиком и полностью основывался на компьютерных симуляциях. Последние представляли собой (в силу необходимости) крайне упрощенные версии реальности и предполагали большое количество допущений, любое из которых могло оказаться ложным. Они — полезные инструменты, способные дать уникальную информацию. Но в конечном счете эти симуляции больше похожи на умозрительные, чем на реальные эксперименты и потому лучше подходят для постановки новых вопросов, а не поиска ответов на уже существующие. Так, если мы хотим узнать, способны ли конкретные люди на стимулирование диффузии идей, информации и, в итоге, воздействия, — и если эти влиятельные люди существуют, какие свойства отличают их от «обычных», — эксперименты нужно проводить в реальном мире. Однако на практике изучать взаимоотношения между индивидуальными влияниями и воздействием в широких масштабах безумно сложно.
Главная загвоздка — в огромных массивах данных, большинство которых очень трудно собрать. Продемонстрировать, что один человек повлиял на другого, — уже проблематично. А если требуется установить их воздействие на более крупные популяции? Необходимо собрать сведения о целых цепочках влияния, в которых один человек влияет на другого, тот — на третьего, и т. д. Очень быстро речь пойдет о тысячах и даже миллионах взаимоотношений. И все это — чтобы отследить распространение одного-единственного фрагмента информации! А ведь в идеале хотелось бы исследовать многие подобные случаи. Для проверки такого вроде бы незамысловатого утверждения — «некоторые люди влиятельнее других, и каким-то образом это важно» — требуется громадный объем данных. Кстати, вот почему так называемые исследования диффузии столь долго окружали различные мифы: когда невозможно ничего доказать, всякий волен предложить любую правдоподобную историю, какая ему нравится. Ведь кто прав — неизвестно.
Впрочем, как и в случае с экспериментами типа «Музыкальной лаборатории», с развитием Интернета ситуация явно начала меняться к лучшему. Сегодня целый ряд новейших исследований диффузии в социальных сетях проводится в масштабе, просто немыслимом каких-то лет 10 назад. Записи в блогах распространяют сообщения и информацию по сетям блогеров. Странички фанатов — по Facebook . Голосовой сервис Instant Messenger — по сети друзей. А участники онлайн-игры Second Life распространяют жесты среди других игроков{134}. Вдохновленные этими исследованиями, мы с коллегами по Yahoo! Джейком Хофманом и Уинтером Мейсоном, а также Эйтеном Бакши, талантливым аспирантом Мичиганского университета, решили поискать лидеров общественного мнения в самой крупной коммуникационной сети, которую только смогли заполучить в свое распоряжение, — в Twitter.
Во многих отношениях Twitter идеально подходит для поиска неформальных лидеров. Во-первых, в отличие от Facebook, например, где люди связываются друг с другом по множеству причин, суть Twitter — в передаче информации «подписчикам», эксплицитно указывающим, что они читают ваши записи. Результирующий «график реципиентов», таким образом, отражает распространение информации по сети друзей и контактов. Во-вторых, эта сеть невероятно многообразна. Основную массу ее пользователей составляют простые люди, чьи подписчики — их настоящие друзья. Но есть здесь пользователи, записи которых читает уйма народа — это общественные деятели (блогеры, журналисты и знаменитости — Эштон Кэтчер, Шакил О’Нил, Опра Уинфри и другие), медиаорганизации (такие как CNN) и даже правительственные и некоммерческие организации (администрация Барака Обамы; Даунинг-стрит, 10[28]; Всемирный экономический форум). Подобное разнообразие позволило нам дать качественную оценку влияния обычных людей так же, как Опры, избежав ряда двусмысленностей, отличавших более ранние представления о лидерах общественного мнения.
Наконец, если одни твиты представляют собой новости о повседневной жизни тех, кто их пишет («Пью кофе в Starbucks на Бродвее! Замечательный день!»), то другие — миллионы — относятся либо к иному контенту (новости или смешные видео), либо к понятиям из внешнего мира (книги, фильмы и т. д.), о которых пользователи Twitter хотят выразить свое мнение. А поскольку формат сети ограничивает объем каждого сообщения 140 знаками, люди часто прибегают к «сокращателям ссылок», заменяющим длинный путаный адрес сайта короткой аккуратной записью вроде http://bit.ly/beRKJo. Преимущество этих укороченных URL в том, что они, по сути, приписывают свой уникальный код каждому сегменту контент-эфира на Twitter. Следовательно, когда пользователь делится интересным твитом, мы можем увидеть, от кого он исходил первоначально, и проследить цепочки диффузии по графику подписчиков.
В общей сложности в течение двух месяцев в конце 2009 года нам удалось отследить более 39 млн таких «событий» диффузии, инициированных более чем 1,6 млн пользователей. Для каждого события мы посчитали количество ретвитов обсуждаемого URL: сперва непосредственными подписчиками пользователя-инициатора («сида»), потом их подписчиками, потом подписчиками их подписчиков, и так далее — в итоге проследив весь каскад ретвитов, запущенных одним-единственным первоначальным твитом. Как показано на схеме ниже, одни каскады были широкими и плоскими, другие — узкими и глубокими. Третьи — очень большими, со сложной структурой: некоторое время они оставались маленькими, а затем вдруг начинали резко увеличиваться. Впрочем, большинство каскадов — примерно 98 % — не распространялись вообще.
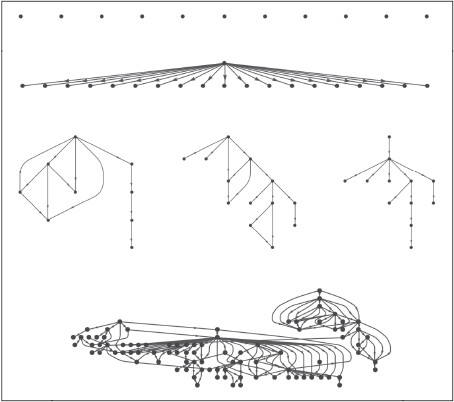
Каскады на Twitter.
Последнее наблюдение крайне важно. Как мы будем подробно обсуждать в следующей главе, стремясь понять, почему некоторые вещи «распространяются как зараза» — загруженные миллионы раз видео с YouTube или смешные послания, циркулирующие по электронной почте или Facebook, — грубейшей ошибкой будет учитывать лишь те немногие из них, которые действительно стали популярными. В большинстве ситуаций изучать можно только «успехи», ибо никто просто-напросто не дает себе труд отслеживать неудачи. Поэтому последние имеют тенденцию очень быстро исчезать в мусорной корзине истории. В сети Twitter, однако, мы можем проследить каждое событие — маленькое или большое. Это, в свою очередь, позволяет установить, кто именно влиятелен, насколько он влиятельнее обычного человека и возможно ли выявить различия между ними так, чтобы это можно было использовать на практике.
Мы старались сымитировать поведение гипотетического маркетолога — то есть, используя знания о свойствах и прошлом поведении примерно миллиона человек, попытаться предсказать, насколько влиятельным каждый из них окажется в будущем. Основываясь на этих прогнозах, маркетолог мог затем «профинансировать» некую группу людей, чтобы она опубликовала необходимую ему информацию, сгенерировав серию каскадов. Чем точнее он мог предсказать величину каскада, инициированного каждым конкретным человеком, тем эффективнее определялся бюджет для спонсируемых твитов.
Проведение такого эксперимента на практике по-прежнему очень трудновыполнимо, поэтому мы сделали все возможное для максимального приближения к реальности. В частности, использовали уже собранные данные, разделив их на две половины: первый месяц стал «историей», а второй — «будущим». Затем мы вложили все наши «исторические» данные в статистическую модель — включая количество подписчиков у каждого пользователя, подписчиков их подписчиков, частоту твитов после регистрации, а также успешность вызывания каскадов в течение этого периода. Потом мы использовали эту модель для предсказания влиятельности каждого пользователя в наших «будущих» данных, а в конце сравнили результаты с тем, что произошло на самом деле.
Если вкратце, то мы обнаружили следующее: прогнозы индивидуального уровня крайне ненадежны. В среднем пользователи с большим количеством подписчиков, успешнее вызывавшие каскады ретвитов в прошлом, действительно имели больше шансов оказаться успешными и в будущем. Но в отдельных случаях наблюдались резкие случайные колебания. Так же как с «Моной Лизой» в предыдущей главе, на каждого человека, проявлявшего качества успешного лидера мнений, приходилось много других людей с теми же самыми качествами, которые, однако, каскадов не вызывали. Не являлась эта неопределенность и следствием нашей неспособности измерить надлежащие качества (в реальности у нас было больше данных, чем обычно бывает у маркетолога) или сделать это аккуратно. Скорее, проблема, как и в случае с вышеописанными симуляциями, заключалась в том, что большая часть факторов, управляющих успешной диффузией, зависит от вещей, находящихся за пределами контроля отдельных сидов. О чем говорит этот результат? Маркетинговые стратегии, фокусирующиеся на горстке «особенных» людей, ненадежны. А значит, оптимальным для маркетологов является подход «портфеля», подразумевающий направленность на большое количество потенциальных лидеров мнений и эксплуатацию их среднего эффекта, что позволяет устранить случайность на уровне индивида.
Будучи многообещающим в теории, подход портфеля ставит вопрос об эффективности затрат или, другими словами, рентабельности. Согласно недавно опубликованной в New York Times статье, например, звезда телевизионного реалити-шоу Ким Кардашьян за твит с упоминанием продукции спонсоров получала 10 тысяч долларов. В то время у нее было больше миллиона подписчиков. Выходит, платить выгоднее ей, а не обычным пользователям со всего-то парой сотен подписчиков. С другой стороны, последние наверняка согласятся упомянуть о некоем продукте за гораздо меньшую сумму. Итак, если более «видные» люди «стоят» дороже, на кого же ориентироваться специалистам по маркетингу: на относительно небольшое количество более влиятельных и «дорогих» или на большое — менее влиятельных и дешевых? А еще лучше — как добиться оптимального баланса?
Прежде всего, ответ на этот вопрос будет зависеть от того, сколько пользователи Twitter захотят получать за свои твиты — если они вообще согласятся на это. Единственный способ сие узнать — попробовать по-настоящему. Мы же провели ряд умозрительных экспериментов, позволивших, во-первых, проверить широкий спектр вероятных допущений, каждое из которых соответствовало разной гипотетической устной маркетинговой кампании, а во-вторых, измерить «доход на инвестиции», используя ту же статистическую модель, что и раньше. Результаты удивили даже нас: будучи действительно влиятельнее обычных людей, кимы кардашьяны стоили настолько дороже, что не оправдывали затрат. С точки зрения распространения информации, наиболее рентабельными оказались «рядовые лидеры мнений» — то есть, люди, чье влияние было средним или даже ниже среднего.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
Глава 15 Лидеры и рядовые члены общества
Глава 15 Лидеры и рядовые члены общества 1Поскольку символы имеют важное практическое значение, политическим лидерам, чтобы добиться успеха, необходимо культивировать символы, способствующие сплачиванию их последователей. Символы играют для рядовых членов организации
ЛИДЕРЫ, ТАНДЕМЫ, ТЕСТЫ
ЛИДЕРЫ, ТАНДЕМЫ, ТЕСТЫ Опекать значит руководить младшими, а также то, что при взаимоотношениях равенства некоторые, самые необходимые основы закладываемых знаний усваиваются лучше обоюдно как у опекуна, так и у опекаемого. 225. Идея совмещения младших и старших классов с
Лидеры стремятся к совершенству
Лидеры стремятся к совершенству Лидер – это тот человек, который выбирает степень совершенства для своей команды. Лидер старается быть лучшим во всем, что он делает. Он постоянно стремится к совершенству в тех областях, где достигаются ключевые результаты. Он
Случайные лидеры мнений
Случайные лидеры мнений Заражение — идея о том, что информация и, предположительно, влияние распространяются по сети точно так же, как инфекционное заболевание по системе физических контактов, — является одной из наиболее интригующих гипотез в науке о сетях{129}. Как
Воздействие на Twitter
Воздействие на Twitter Всегда весело наблюдать за человеком, который впервые начинает пользоваться Facebook или Twitter. Он регистрируется, говорит что-то невнятное и наблюдает за реакцией окружающего мира:«Класс! Я получил сообщение от Лизы… Как она меня так быстро нашла?»«Эй! Я
Лидеры, контактники и аналитики
Лидеры, контактники и аналитики Лидеры Лидер входит в помещение. Это не остается незамеченным. Уж если он здесь, то он здесь. И разве поблизости есть кто-то еще? Впрочем, неважно. Главное, что его видят все. Некоторые люди его побаиваются, так как он кажется им слишком
Лидеры
Лидеры Лидер входит в помещение. Это не остается незамеченным. Уж если он здесь, то он здесь. И разве поблизости есть кто-то еще? Впрочем, неважно. Главное, что его видят все. Некоторые люди его побаиваются, так как он кажется им слишком самоуверенным. Он не стесняется
Лидеры
Лидеры Вы произведете на лидера убедительное впечатление, если будете вести себя самоуверенно, возможно, даже вызывающе по отношению к нему. Делайте все, чтобы он не скучал. Если у вас завязался роман с лидером, то не ждите, что он каждый вечер будет сидеть с вами в обнимку
Лидеры мирового развития
Лидеры мирового развития Большинство специалистов согласны с тем, что синтез античности и варварских народов завершился к 11–12 векам. Кончился период упадка: переживание наследия Рима. Начала подниматься новая цивилизация – европейская. До 16–17 веков продолжается
Лидеры — это национальный ресурс страны
Лидеры — это национальный ресурс страны Фирма «Арго» доказала всем своим существованием, что она умеет привлекать и воспитывать лидеров. Но стихийное лидерство грешит несовершенством, потому что основано на интуиции. А интуиция сама по себе штука хорошая, но часто
Я бы в лидеры пошел…
Я бы в лидеры пошел… После мини-тренинга «Обратный отсчет» приходит много вопросов, и один из вопросов показался мне
Современные лидеры
Современные лидеры У нынешних лидеров есть возможность, и даже обязанность, знать устройство и образ действия человеческого мозга. За последние 20 лет наши знания в этих вопросах существенно возросли. И те, кто ими не пользуется, оказываются в невыгодном положении. В
19. Не все лидеры одинаковы
19. Не все лидеры одинаковы Многие руководители подходят ко мне после презентаций и спрашивают о моем утверждении «каждый – лидер». Я заметил, что у всех лучших компаний на планете есть одна общая черта: они выращивают лидеров внутри организации быстрее, чем их