Обогащенная модель ТОТЕ
Таким образом, основоположники НЛП открыли – или изобрели, или отшлифовали – модель Стратегий, исходя из модели ТОТЕ, которую когнитивные психологи разработали в качестве более полной и усовершенствованной старой модели «стимул-реакция». Такова «связь времен» между моделями. Кожибски объяснял, что мы связываем время, когда развиваем идеи и открытия своих предшественников-изобретателей, так что нам не приходится заново изобретать компьютер.
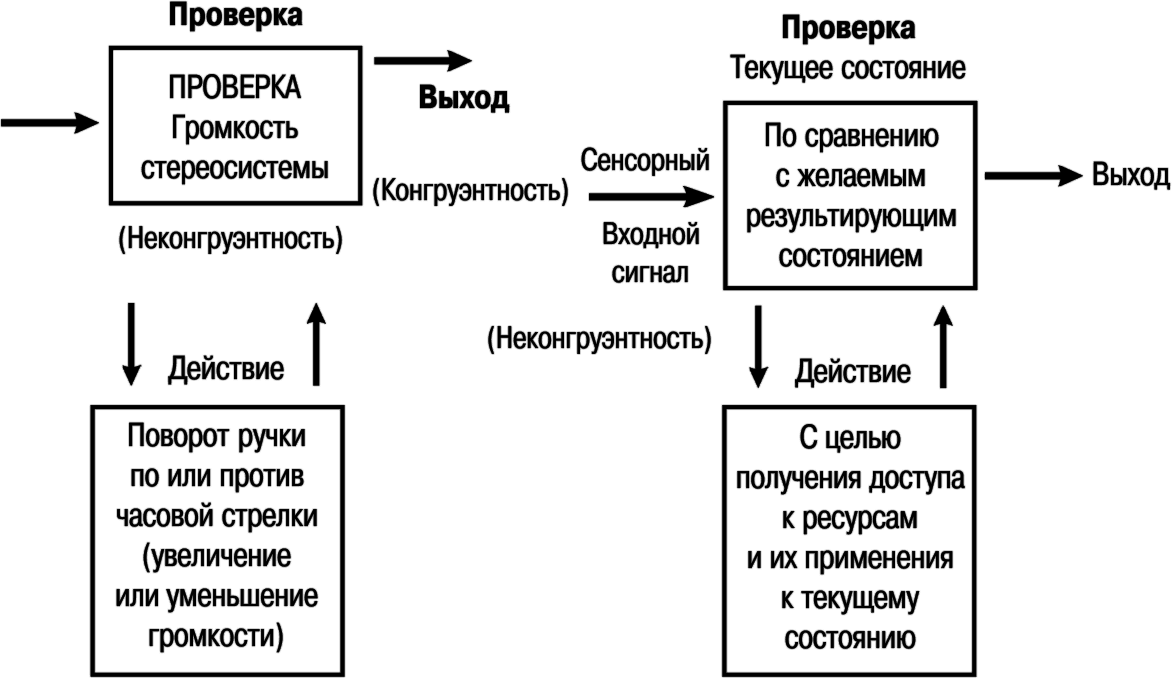
Рис. 16.2. Диаграмма модели ТОТЕ
ТОТЕ обеспечивает базовый формат для описания конкретных последовательностей форм поведения. Она описывает последовательность форм активности, которая консолидируется в функциональную единицу поведения, как правило, реализуемую на уровне, лежащем ниже порога осознания. Затем, обозначив этот процесс как ментальную стратегию, Дилтс, Бэндлер, Гриндер, Кэмерон-Бэндлер и Делозье (1980) интегрировали ТОТЕ в качестве шаблона в модель НЛП. Тем самым они обогатили и расширили модель ТОТЕ, так что она включила такие репрезентативные составляющие, как сенсорные репрезентативные системы, различения этих сенсорных модальностей («суб-модальности»), ключи зрительного доступа и лингвистические предикаты.
Результатом этого явилась модель, позволяющая нам распаковывать бессознательные стратегии, якорить элементы друг с другом, рефреймировать заключенные в них смыслы, а также проектировать, перепроектировать и/или встраивать стратегии. Эти нововведения сделали модель более приспособленной к моделированию опыта, позволяя заглянуть дальше и глубже в «черный ящик». В то же время эта модель обеспечила нам значительно более широкий и точный спектр языковых средств.
В этих отношениях НЛП еще более усовершенствовало модель ТОТЕ. Новая модель точно указывала, как мы осуществляем проверку и действия с точки зрения сенсорных систем, а также с точки зрения конкретных особенностей этих систем. Переформулировав Условия проверки и Действия как осуществляемые посредством репрезентативных систем, основоположники НЛП значительно усовершенствовали модели С-Р и ТОТЕ.
Например, чтобы протестировать нечто, можно сравнить внешние/внутренние визуально запоминаемые образы (Ve/Vi): «Выглядит ли написание этого слова так, как оно должно выглядеть согласно моим воспоминаниям?»
Можно проделать то же самое с кинестетической (Kе/Кi) или аудиальной системой (Ае/Аi). Опыт конгруэнтности (который заставляет нас ходить по замкнутой петле в пределах программы) также проявляется в виде репрезентаций, относящихся к той или иной репрезентативной системе.
Эта модель также позволяет провести проверку на сравнение двух внутренних сохраняемых или генерируемых репрезентаций. Такая проверка может касаться, скажем, интенсивности, размеров или цвета репрезентаций. Может потребоваться, чтобы интенсивность некоторого ощущения, звукового или зрительного образа достигла определенного порогового значения, прежде чем будет получен достаточно сильный сигнал, чтобы можно было выйти из программы.
Поскольку большинство людей, как правило, предпочитают использовать одну репрезентативную систему (PC) намного чаще, чем другие, очередность использования PC описывает то, как мы используем наиболее высоко ценимую нами PC при проведении Проверок и выполнении Действий. Мы часто используем предпочитаемую нами PC даже тогда, когда она функционирует не лучшим образом, а порой даже порождает проблемы и ограничения.
В усовершенствованной модели Стратегий НЛП эффективность моделирования часто предполагает сопоставление адекватной PC с задачей (например, визуальной PC с правописанием или аудиальной – с музыкой). Именно это и является одной из целей ТОТЕ и PC-анализа – нахождение PC, наиболее адекватной для шагов ТОТЕ, что позволяет нам получить желаемый результат за наименьшее число шагов. Если нам это удается, мы говорим, что наша модель элегантна. Модель Стратегий придает нашим PC новый смысл и мотивацию. Она показывает, что все наши PC представляют собой ресурсы, способствующие обучению и выполнению заданий.
Рассмотрим, к примеру, стратегии обучения правописанию. Фонетическая стратегия обучения правописанию предполагает последовательность: Ае’Аi/Ае. Однако поскольку визуальное кодирование английского языка не следует фонетическим правилам, люди, использующие визуальные стратегии правописания, систематически показывают лучшие результаты, чем те, кто использует аудиальные стратегии. Стратегия произнесения вслух работает очень эффективно для устных выступлений с чтением по бумажке. В то же время она не столь эффективна для правописания. Типичная визуальная стратегия обучения правописанию содержит последовательность шагов, показанную на рис. 16.3.
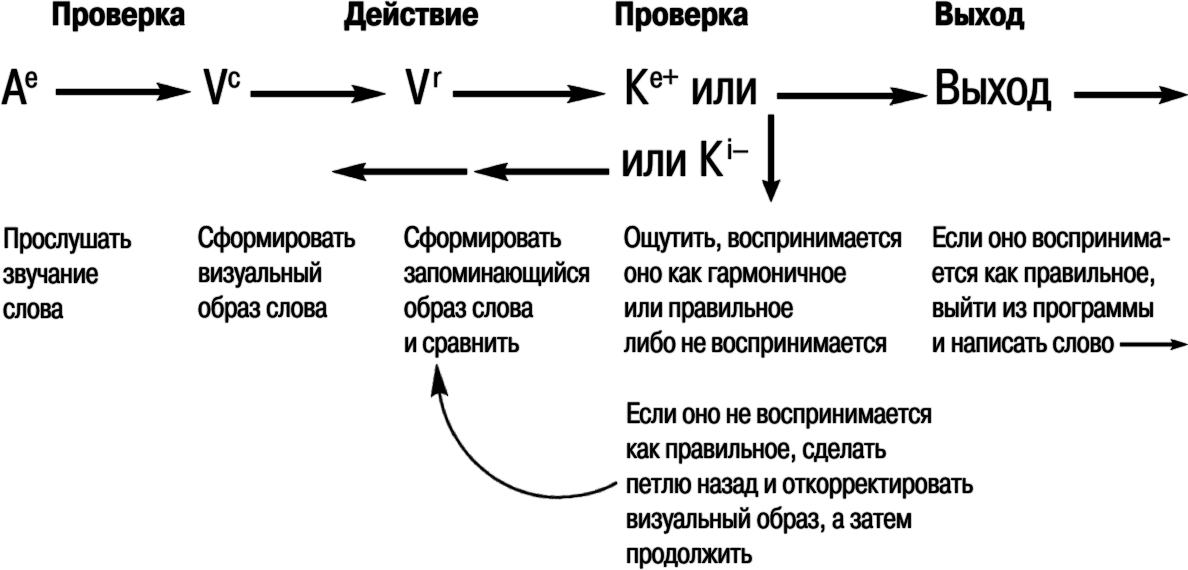
Рис. 16.3. ТОТЕ для правописания
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК