Приложение Б. Статистика и обработка данных
Приложение Б. Статистика и обработка данных
Введение
Слово «статистика» часто ассоциируется со словом «математика», и это пугает студентов, связывающих это понятие со сложными формулами, требующими высокого уровня абстрагирования.
Однако, как говорит Мак-Коннелл, статистика — это прежде всего способ мышления, и для ее применения нужно лишь иметь немного здравого смысла и знать основы математики. В нашей повседневной жизни мы, сами о том не догадываясь, постоянно занимаемся статистикой. Хотим ли мы спланировать бюджет, рассчитать потребление бензина автомашиной, оценить усилия, которые потребуются для усвоения какого-то курса, с учетом полученных до сих пор отметок, предусмотреть вероятность хорошей и плохой погоды по метеорологической сводке или вообще оценить, как повлияет то или иное событие на наше личное или совместное будущее, — нам постоянно приходится отбирать, классифицировать и упорядочивать информацию, связывать ее с другими данными так, чтобы можно было сделать выводы, позволяющие принять верное решение.
Все эти виды деятельности мало отличаются от тех операций, которые лежат в основе научного исследования и состоят в синтезе данных, полученных на различных группах объектов в том или ином эксперименте, в их сравнении с целью выяснить черты различия между ними, в их сопоставлении с целью выявить показатели, изменяющиеся в одном направлении, и, наконец, в предсказании определенных фактов на основании тех выводов, к которым приводят полученные результаты. Именно в этом заключается цель статистики в науках вообще, особенно в гуманитарных. В последних нет ничего абсолютно достоверного, и без статистики выводы в большинстве случаев были бы чисто интуитивными и не могли бы составлять солидную основу для интерпретации данных, полученных в других исследованиях.
Для того чтобы оценить огромные преимущества, которые может дать статистика, мы попробуем проследить за ходом расшифровки и обработки данных, полученных в эксперименте. Тем самым, исходя из конкретных результатов и тех вопросов, которые они ставят перед исследователем, мы сможем разобраться в различных методиках и несложных способах их применения. Однако, перед тем как приступить к этой работе, нам будет полезно рассмотреть в самых общих чертах три главных раздела статистики.
1. Описательная статистика, как следует из названия, позволяет описывать, подытоживать и воспроизводить в виде таблиц или графиков данные того или иного распределения, вычислять среднее для данного распределения и его размах и дисперсию.
2. Задача индуктивной статистики — проверка того, можно ли распространить результаты, полученные на данной выборке, на всю популяцию, из которой взята эта выборка. Иными словами, правила этого раздела статистики позволяют выяснить, до какой степени можно путем индукции обобщить на большее число объектов ту или иную закономерность, обнаруженную при изучении их ограниченной группы в ходе какого-либо наблюдения или эксперимента. Таким образом, при помощи индуктивной статистики делают какие-то выводы и обобщения, исходя из данных, полученных при изучении выборки.
3. Наконец, измерение корреляции позволяет узнать, насколько связаны между собой две переменные, с тем чтобы можно было предсказывать возможные значения одной из них, если мы знаем другую.
Существуют две разновидности статистических методов или тестов, позволяющих делать обобщение или вычислять степень корреляции. Первая разновидность — это наиболее широко применяемые параметрические методы, в которых используются такие параметры, как среднее значение или дисперсия данных. Вторая разновидность — это непараметрические методы, оказывающие неоценимую услугу в том случае, когда исследователь имеет дело с очень малыми выборками или с качественными данными (см. документ Б.1); эти методы очень просты с точки зрения как расчетов, так и применения. Когда мы познакомимся с различными способами описания данных и перейдем к их статистическому анализу, мы рассмотрим обе эти разновидности.
Как уже говорилось, для того чтобы попытаться разобраться в этих различных областях статистики, мы попробуем ответить на те вопросы, которые возникают в связи с результатами того или иного исследования. В качестве примера мы возьмём тот эксперимент, который приведен в главе 3, а именно — изучение влияния потребления марихуаны на глазодвигательную координацию и на время реакции. Методика, используемая в этом гипотетическом эксперименте, а также результаты, которые мы могли бы в нем получить, представлены в дополнении Б.2 [197].
При желании вы можете заменить какие-то конкретные детали этого эксперимента на другие — например, потребление марихуаны на потребление алкоголя или лишение сна, — или, что еще лучше, подставить вместо этих гипотетических данных те, которые вы действительно получили в вашем собственном исследовании. В любом случае вам придется принять «правила нашей игры» и выполнять те расчеты, которые здесь от вас потребуются; только при этом условии до вас «дойдет» существо предмета, если это уже не случилось с вами раньше [198].
Дополнение Б.1. Некоторые основные понятия
Популяция и выборка
[199]
Одна из задач статистики состоит в том, чтобы анализировать данные, полученные на части популяции, с целью сделать выводы относительно популяции в целом.
Популяция в статистике не обязательно означает какую-либо группу людей или естественное сообщество; этот термин относится ко всем существам или предметам, образующим общую изучаемую совокупность, будь то атомы или студенты, посещающие то или иное кафе.
Выборка — это небольшое количество элементов, отобранных с помощью научных методов так, чтобы она была репрезентативной, т. е. отражала популяцию в целом.
Данные и их разновидности
Данные в статистике — это основные элементы, подлежащие анализу. Данными могут быть какие-то количественные результаты, свойства, присущие определенным членам популяции, место в той или иной последовательности — в общем любая информация, которая может быть классифицирована или разбита на категории с целью обработки [200].
Построение распределения — это разделение первичных данных, полученных на выборке, на классы или категории с целью получить обобщенную упорядоченную картину, позволяющую их анализировать.
Существуют три типа данных:
1. Количественные данные, получаемые при измерениях (например, данные о весе, размерах, температуре, времени, результатах тестирования и т. п.). Их можно распределить по шкале с равными интервалами.
2. Порядковые данные, соответствующие местам этих элементов в последовательности, полученной при их расположении в возрастающем порядке (1-й…, 7-й…, 100-й…; А, Б, В…).
3. Качественные данные, представляющие собой какие-то свойства элементов выборки или популяции. Их нельзя измерить, и единственной их количественной оценкой служит частота встречаемости (число лиц с голубыми или с зелеными глазами, курильщиков и не курильщиков, утомленных и отдохнувших, сильных и слабых и т. п.).
Из всех этих типов данных только количественные данные можно анализировать с помощью методов, в основе которых лежат параметры (такие, например, как средняя арифметическая). Но даже к количественным данным такие методы можно применить лишь в том случае, если число этих данных достаточно, чтобы проявилось нормальное распределение. Итак, для использования параметрических методов в принципе необходимы три условия: данные должны быть количественными, их число должно быть достаточным, а их распределение — нормальным. Во всех остальных случаях всегда рекомендуется использовать непараметрические методы.
Дополнение Б.2. Влияние потребления марихуаны на глазодвигательную координацию и время реакции (гипотетический эксперимент)
Процедура
На группе из 30 добровольцев — студентов и студенток, курящих обычные сигареты, но не марихуану, — был проведен опыт по изучению глазодвигательной координации. Задача испытуемых заключалась в том, чтобы поражать предъявляемые на дисплее движущиеся мишени, манипулируя подвижным рычагом. Каждому испытуемому были предъявлены 10 последовательностей из 25 мишеней.
Для того чтобы установить исходный уровень, рассчитали среднее число попаданий из 25, а также среднее время реакции для 250 попыток. Далее группа была разделена на две подгруппы как можно более равным образом. Семь девушек и восемь юношей из контрольной группы получили сигарету с обычным табаком и сушеной травой, дым от которой напоминал по запаху дым марихуаны. В отличие от этого семь девушек и восемь юношей из опытной (экспериментальной) группы получили сигарету с табаком и марихуаной. Выкурив сигарету, каждый испытуемый снова был подвергнут тесту на глазодвигательную координацию. (Более подробно этот опыт описан в главе 3).
В табл. Б.2.1 и Б.2.2 представлены средние результаты обоих измерений для испытуемых той и другой группы до и после воздействия.
Таблица Б.2.1. Результативность испытуемых контрольной и опытной групп (среднее число пораженных мишеней из 25 в 10 сериях испытаний)
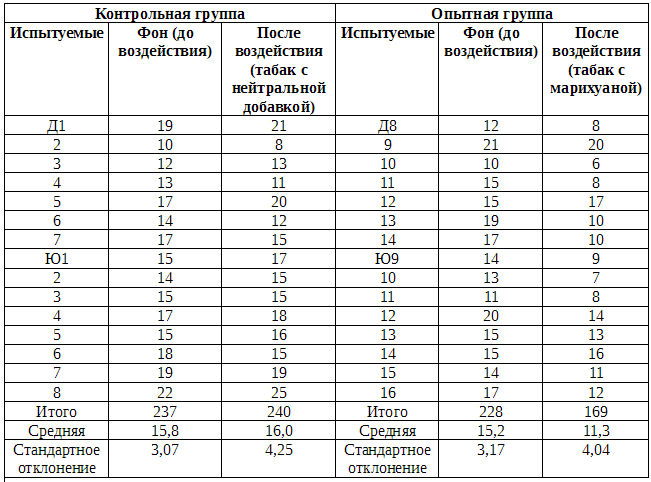
Примечание: девушки: Д1-Д14; юноши: Ю1-Ю16.
Таблица Б.2.2. Время реакции испытуемых контрольной и опытной групп (среднее время 1/10 с в серии из 10 испытаний)
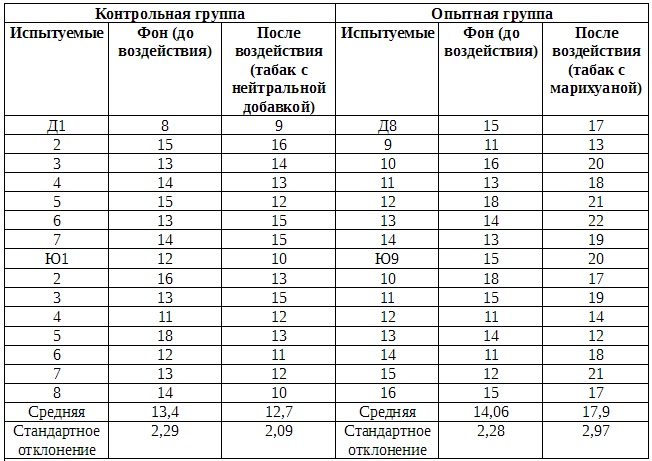
Примечание: девушки: Д1-Д14; юноши: Ю1-Ю16.
Описательная статистика
Описательная статистика позволяет обобщать первичные результаты, полученные при наблюдении или в эксперименте. Процедуры здесь сводятся к группировке данных по их значениям, построению распределения их частот, выявлению центральных тенденций распределения (например, средней арифметической) и, наконец, к оценке разброса данных по отношению к найденной центральной тенденции.
Группировка данных
Для группировки необходимо прежде всего расположить данные каждой выборки в возрастающем порядке. Так, в нашем эксперименте для переменной «число пораженных мишеней» данные будут располагаться следующим образом:
Контрольная группа

Опытная группа (дополнить цифрами)
Фон:……….
После воздействия:……….
Распределение частот (числ? пораженных мишеней)
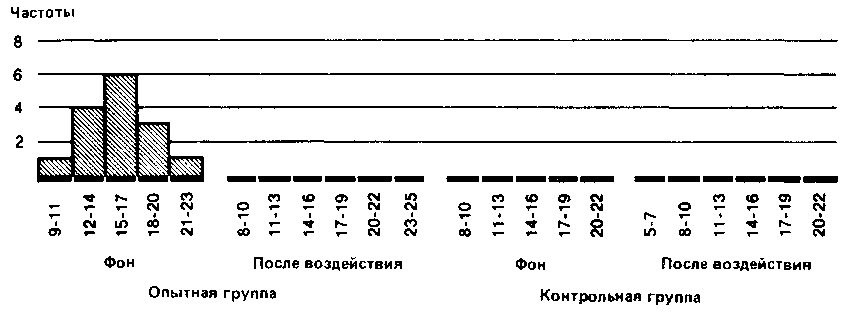
Уже при первом взгляде на полученные ряды можно заметить, что многие данные принимают одни и те же значения, причем одни значения встречаются чаще, а другие — реже. Поэтому было бы интересно вначале графически представить распределение различных значений с учетом их частот. При этом получают следующие столбиковые диаграммы:

Такое распределение данных по их значениям дает нам уже гораздо больше, чем представление в виде рядов. Однако подобную группировку используют в основном лишь для качественных данных, четко разделяющихся на обособленные категории (см. дополнение Б.1).
Что касается количественных данных, то они всегда располагаются на непрерывной шкале и, как правило, весьма многочисленны. Поэтому такие данные предпочитают группировать по классам, чтобы яснее видна была основная тенденция распределения.
Такая группировка состоит в основном в том, что объединяют данные с одинаковыми или близкими значениями в классы и определяют частоту для каждого класса. Способ разбиения на классы зависит от того, что именно экспериментатор хочет выявить при разделении измерительной шкалы на равные интервалы. Например, в нашем случае можно сгруппировать данные по классам с интервалами в две или три единицы шкалы:
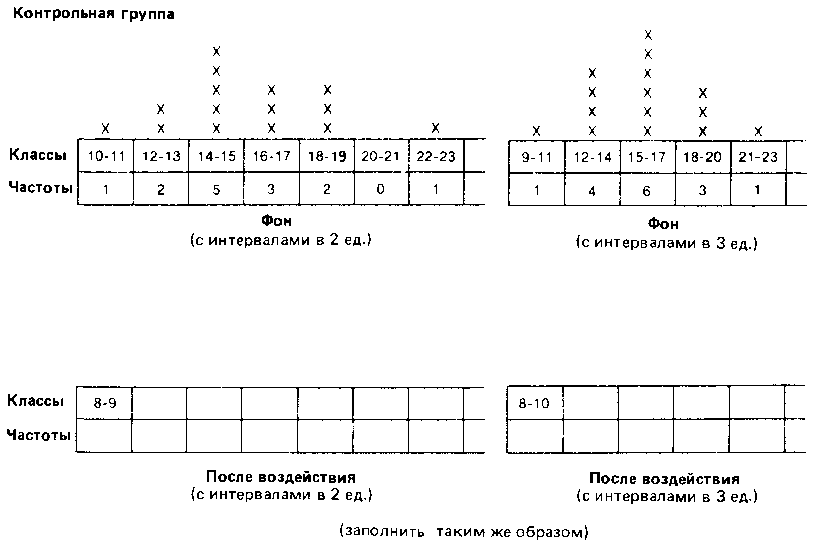
Выбор того или иного типа группировки зависит от различных соображений. Так, в нашем случае группировка с интервалами между классами в две единицы хорошо выявляет распределение результатов вокруг центрального «пика». В то же время группировка с интервалами в три единицы обладает тем преимуществом, что дает более обобщенную и упрощенную картину распределения, особенно если учесть, что число элементов в каждом классе невелико [201]. Именно поэтому в дальнейшем мы будем оперировать классами в три единицы.
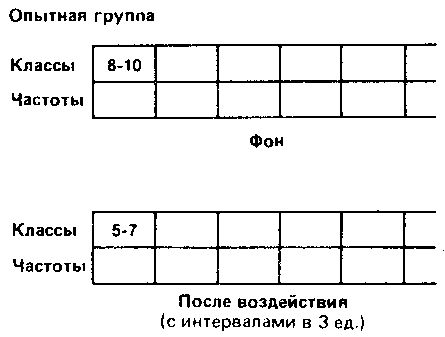
Данные, разбитые на классы по непрерывной шкале, нельзя представить графически так, как это сделано выше. Поэтому предпочитают использовать так называемые гистограммы — способ графического представления в виде примыкающих друг к другу прямоугольников:
Наконец, для еще более наглядного представления общей конфигурации распределения можно строить полигоны распределения частот. Для этого отрезками прямых соединяют центры верхних сторон всех прямоугольников гистограммы, а затем с обеих сторон «замыкают» площадь под кривой, доводя концы полигонов до горизонтальной оси (частота = 0) в точках, соответствующих самым крайним значениям распределения. При этом получают следующую картину:

Если сравнить полигоны, например, для фоновых (исходных) значений контрольной группы и значений после воздействия для опытной группы, то можно будет увидеть, что в первом случае полигон почти симметричен (т. е. если сложить полигон вдвое по вертикали, проходящей через его середину, то обе половины наложатся друг на друга), тогда как для экспериментальной группы он асимметричен и смещен влево (так что справа у него как бы вытянутый шлейф).
Полигон для фоновых данных контрольной группы сравнительно близок к идеальной кривой, которая могла бы получиться для бесконечно большой популяции. Такая кривая — кривая нормального распределения — имеет колоколообразную форму и строго симметрична. Если же количество данных ограничено (как в выборках, используемых для научных исследований), то в лучшем случае получают лишь некоторое приближение (аппроксимацию) к кривой нормального распределения. Если вы построите полигон для фоновых значений опытной группы и значений после воздействия для контрольной группы, то вы наверняка заметите, что так же будет обстоять дело и в этих случаях.
Оценка центральной тенденции
Если распределения для контрольной группы и для фоновых значений в опытной группе более или менее симметричны, то значения, получаемые в опытной группе после воздействия, группируются, как уже говорилось, больше в левой части кривой. Это говорит о том, что после употребления марихуаны выявляется тенденция к ухудшению показателей у большого числа испытуемых.
Для того чтобы выразить подобные тенденции количественно, используют три вида показателей моду, медиану и среднюю.
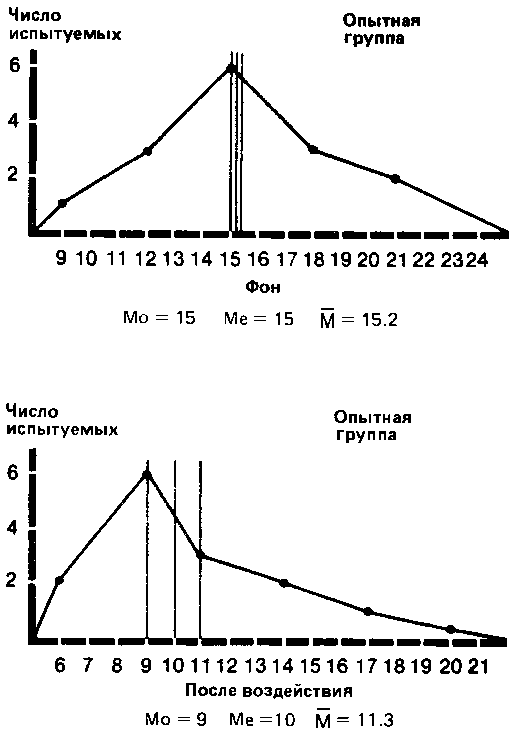
1. Мода (Mo) — это самый простой из всех трех показателей. Она соответствует либо наиболее частому значению, либо среднему значению класса с наибольшей частотой. Так, в нашем примере для экспериментальной группы мода для фона будет равна 15 (этот результат встречается четыре раза и находится в середине класса 14-15-16), а после воздействия — 9 (середина класса 8-9-10).
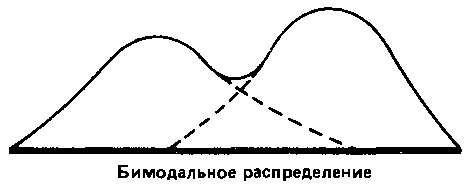
Мода используется редко и главным образом для того, чтобы дать общее представление о распределении. В некоторых случаях у распределения могут быть две моды; тогда говорят о бимодальном распределении. Такая картина указывает на то, что в данном совокупности имеются две относительно самостоятельные группы (см., например, данные Триона, приведенные в документе 3.5).
2. Медиана (Me) соответствует центральному значению в последовательном ряду всех полученных значений. Так, для фона в экспериментальной группе, где мы имеем ряд
10, 11, 12, 13, 14, 14, 15, 15, 15, 15, 17, 17, 19, 20, 21;
медиана соответствует 8-му значению, т. е. 15. Для результатов воздействия в экспериментальной группе она равна 10.
В случае если число данных n, четное, медиана равна средней арифметической между значениями, находящимися в ряду на n/2-м и n/2+1-м местах. Так, для результатов воздействия для восьми юношей опытной группы медиана располагается между значениями, находящимися на 4-м (8/2 = 4) и 5-м местах в ряду. Если выписать весь ряд для этих данных, а именно
7, 8, 9, 11, 12, 13, 14, 16;
то окажется, что медиана соответствует (11 + 12)/2 = 11,5 (видно, что медиана не соответствует здесь ни одному из полученных значений).
3. Средняя арифметическая (
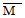 ) (далее просто «средняя») — это наиболее часто используемый показатель центральной тенденции. Ее применяют, в частности, в расчетах, необходимых для описания распределения и для его дальнейшего анализа. Ее вычисляют, разделив сумму всех значений данных на число этих данных. Так, для нашей опытной группы она составит 15,2 (228/15) для фона и 11,3 (169/15) для результатов воздействия.
) (далее просто «средняя») — это наиболее часто используемый показатель центральной тенденции. Ее применяют, в частности, в расчетах, необходимых для описания распределения и для его дальнейшего анализа. Ее вычисляют, разделив сумму всех значений данных на число этих данных. Так, для нашей опытной группы она составит 15,2 (228/15) для фона и 11,3 (169/15) для результатов воздействия.
Если теперь отметить все эти три параметра на каждой из кривых для экспериментальной группы, то будет видно, что при нормальном распределении они более или менее совпадают, а при асимметричном распределении — нет.
Прежде чем идти дальше, полезно будет вычислить все эти показатели для обеих распределений контрольной группы — они пригодятся нам в дальнейшем:
Оценка разброса
Как мы уже отмечали, характер распределения результатов после воздействия изучаемого фактора в опытной группе дает существенную информацию о том, как испытуемые выполняли задание. Сказанное относится и к обоим распределениям в контрольной группе:
Сразу бросается в глаза, что если средняя в обоих случаях почти одинакова, то во втором распределении результаты больше разбросаны, чем в первом. В таких случаях говорят, что у второго распределения больше диапазон, или размах вариаций, т. е. разница между максимальным и минимальным значениями.
Так, если взять контрольную группу, то диапазон распределения для фона составит 22–10 = 12, а после воздействия 25 — 8 = 17. Это позволяет предположить, что повторное выполнение задачи на глазодвигательную координацию оказало на испытуемых из контрольной группы определенное влияние: у одних показатели улучшились, у других ухудшились [202]. Однако для количественной оценки разброса результатов относительно средней в том или ином распределении существуют более точные методы, чем измерение диапазона.
Чаще всего для оценки разброса определяют отклонение каждого из полученных значений от средней (M —
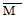 ), обозначаемое буквой d, а затем вычисляют среднюю арифметическую всех этих отклонений. Чем она больше, тем больше разброс данных и тем более разнородна выборка. Напротив, если эта средняя невелика, то данные больше сконцентрированы относительно их среднего значения и выборка более однородна.
), обозначаемое буквой d, а затем вычисляют среднюю арифметическую всех этих отклонений. Чем она больше, тем больше разброс данных и тем более разнородна выборка. Напротив, если эта средняя невелика, то данные больше сконцентрированы относительно их среднего значения и выборка более однородна.
Итак, первый показатель, используемый для оценки разброса, — это среднее отклонение. Его вычисляют следующим образом (пример, который мы здесь приведем, не имеет ничего общего с нашим гипотетическим экспериментом). Собрав все данные и расположив их в ряд
3, 5, 6, 9, 11, 14;
находят среднюю арифметическую для выборки:
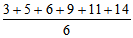 =
=
 = 8.
= 8.
Затем вычисляют отклонения каждого значения от средней и суммируют их:
(3–8) + (5–8) + (6–8) + (9–8) + (11 — 8) + (14 — 8) = (-5) + (-3) + (-2) + (+1) + (+3) + (+6).
Однако при таком сложении отрицательные и положительные отклонения будут уничтожать друг друга, иногда даже полностью, так что результат (как в данном примере) может оказаться равным нулю. Из этого ясно, что нужно находить сумму абсолютных значений индивидуальных отклонений и уже эту сумму делить на их общее число. При этом получится следующий результат:
Среднее отклонение равно
 =
=
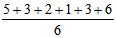 =
=
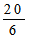 = 33,3.
= 33,3.
Общая формула:
Среднее отклонение =
 ,
,
где ? (сигма) означает сумму; |d| — абсолютное значение каждого индивидуального отклонения от средней; n — число данных.
Однако абсолютными значениями довольно трудно оперировать в алгебраических формулах, используемых в более сложном статистическом анализе. Поэтому статистики решили пойти по «обходному пути», позволяющему отказаться от значений с отрицательным знаком, а именно возводить все значения в квадрат, а затем делить сумму квадратов на число данных. В нашем примере это выглядит следующим образом:
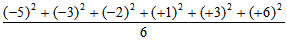 =
=
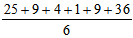 =
=
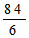 = 14.
= 14.
В результате такого расчета получают так называемую вариансу [203]. Формула для вычисления вариансы, таким образом, следующая:
Варианса =
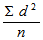 .
.
[204]
Наконец, чтобы получить показатель, сопоставимый по величине со средним отклонением, статистики решили извлекать из вариансы квадратный корень. При этом получается так называемое стандартное отклонение:
Стандартное отклонение =
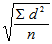 .
.
В нашем примере стандартное отклонение равно
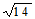 = 3,74.
= 3,74.
Следует еще добавить, что для того, чтобы более точно оценить стандартное отклонение для малых выборок (с числом элементов менее 30), в знаменателе выражения под корнем надо использовать не n, а n — 1:
? =
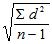 . [205]
. [205]
Вернёмся теперь к нашему эксперименту и посмотрим, насколько полезен оказывается этот показатель для описания выборок.
На первом этапе, разумеется, необходимо вычислить стандартное отклонение для всех четырех распределений. Сделаем это сначала для фона опытной группы:
Расчет стандартного отклонения для фона контрольной группы
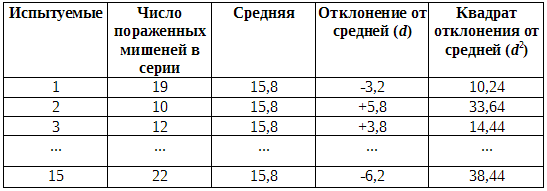
Сумма (?) d2 = 131,94
Варианса (s2) =
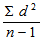 =
=
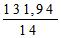 = 9,42.
= 9,42.
Стандартное отклонение (s) =
 =
=
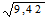 = 3,07.
= 3,07.
Примечание: Формула для расчетов и сами расчеты приведены здесь лишь в качестве иллюстрации. В наше время гораздо проще приобрести такой карманный микрокалькулятор, в котором подобные расчеты уже заранее запрограммированы, и для расчета стандартного отклонения достаточно лишь ввести данные, а затем нажать клавишу s.
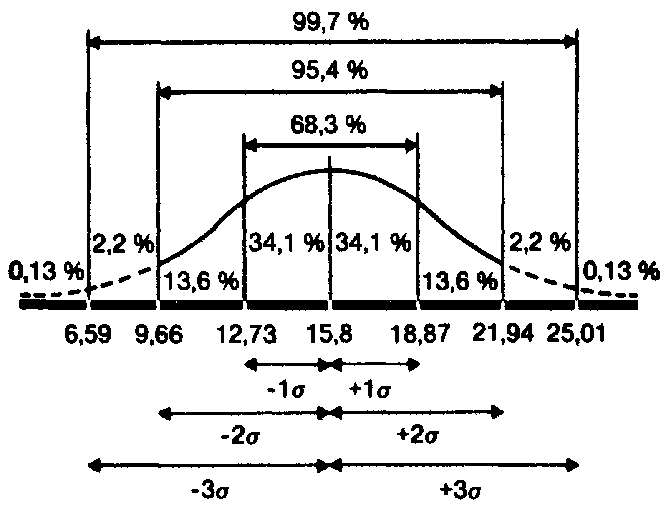
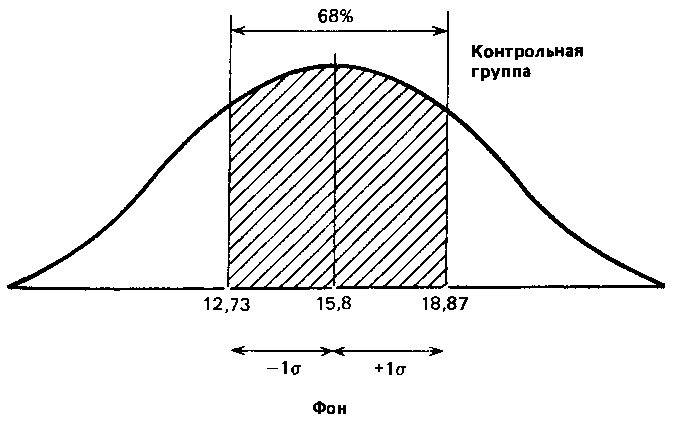
О чем же свидетельствует стандартное отклонение, равное 3,07? Оказывается, оно позволяет сказать, что большая часть результатов (выраженных здесь числом пораженных мишеней) располагается в пределах 3,07 от средней, т. е. между 12,73 (15,8–3,07) и 18,87 (15,8 + 3,07).
Для того чтобы лучше понять, что подразумевается под «большей частью результатов», нужно сначала рассмотреть те свойства стандартного отклонения, которые проявляются при изучении популяции с нормальным распределением.
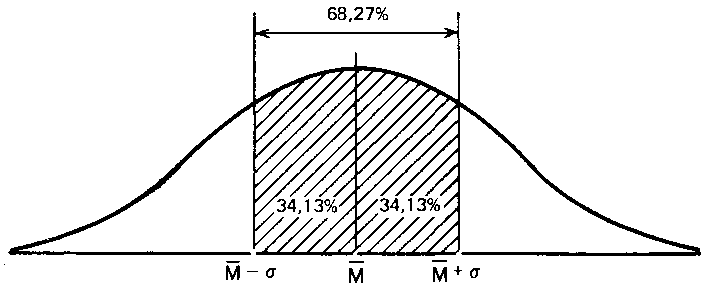
Статистики показали, что при нормальном распределении «большая часть» результатов, располагающаяся в пределах одного стандартного отклонения по обе стороны от средней, в процентном отношении всегда одна и та же и не зависит от величины стандартного отклонения: она соответствует 68 % популяции (т. е. 34 % ее элементов располагается слева и 34 % — справа от средней):
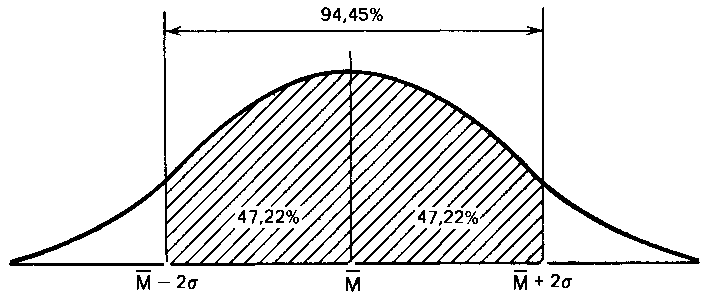
Точно так же рассчитали, что 94,45 % элементов популяции при нормальном распределении не выходит за пределы двух стандартных отклонений от средней:
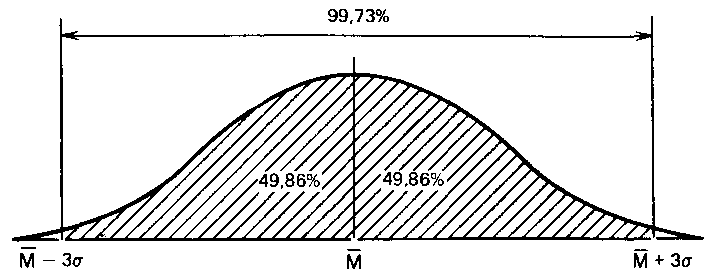
и что в пределах трех стандартных отклонений умещается почти вся популяция — 99,73 %.
Учитывая, что распределение частот фона контрольной группы довольно близко к нормальному, можно полагать, что 68 % членов всей популяции, из которой взята выборка, тоже будет получать сходные результаты, т. е. попадать примерно в 13–19 мишеней из 25. Распределение результатов остальных членов популяции должно выглядеть следующим образом:
Гипотетическая популяция, из которой взята контрольная группа (фон)
Что касается результатов той же группы после воздействия изучаемого фактора, то стандартное отклонение для них оказалось равным 4,25 (пораженных мишеней). Значит, можно предположить, что 68 % результатов будут располагаться именно в этом диапазоне отклонений от средней, составляющей 16 мишеней, т. е. в пределах от 11,75 (16 — 4,25) до 20,25 (16 + 4,25), или, округляя, 12–20 мишеней из 25. Видно, что здесь разброс результатов больше, чем в фоне. Эту разницу в разбросе между двумя выборками для контрольной группы можно графически представить следующим образом:

Поскольку стандартное отклонение всегда соответствует одному и тому же проценту результатов, укладывающихся в его пределах вокруг средней, можно утверждать, что при любой форме кривой нормального распределения та доля ее площади, которая ограничена (с обеих сторон) стандартным отклонением, всегда одинакова и соответствует одной и той же доле всей популяции. Это можно проверить на тех наших выборках, для которых распределение близко к нормальному, — на данных о фоне для контрольной и опытной групп.
Итак, ознакомившись с описательной статистикой, мы узнали, как можно представить графически и оценить количественно степень разброса данных в том или ином распределении. Тем самым мы смогли понять, чем различаются в нашем опыте распределения для контрольной группы до и после воздействия. Однако можно ли о чем-то судить по этой разнице — отражает ли она действительность или же это просто артефакт, связанный со слишком малым объемом выборки? Тот же вопрос (только еще острее) встаёт и в отношении экспериментальной группы, подвергнутой воздействию независимой переменной. В этой группе стандартное отклонение для фона и после воздействия тоже различается примерно на 1 (3,14 и 4,04 соответственно). Однако здесь особенно велика разница между средними — 15,2 и 11,3. На основании чего можно было бы утверждать, что эта разность средних действительно достоверна, т. е. достаточно велика, чтобы можно было с уверенностью объяснить ее влиянием независимой переменной, а не простой случайностью? В какой степени можно опираться на эти результаты и распространять их на всю популяцию, из которой взята выборка, т. е. утверждать, что потребление марихуаны и в самом деле обычно ведёт к нарушению глазодвигательной координации?
На все эти вопросы и пытается дать ответ индуктивная статистика.
Индуктивная статистика
Задачи индуктивной статистики заключаются в том, чтобы определять, насколько вероятно, что две выборки принадлежат к одной популяции.
Давайте наложим друг на друга, с одной стороны, две кривые — до и после воздействия — для контрольной группы и, с другой стороны, две аналогичные кривые для опытной группы. При этом масштаб кривых должен быть одинаковым.
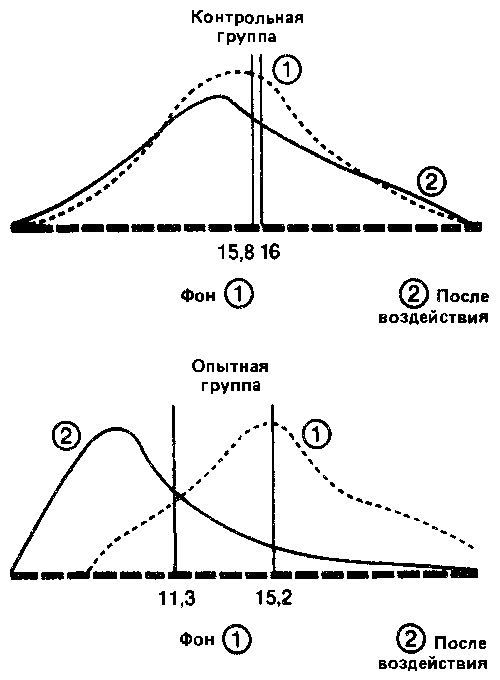
Видно, что в контрольной группе разница между средними обоих распределений невелика, и поэтому можно думать, что обе выборки принадлежат к одной и той же популяции. Напротив, в опытной группе большая разность между средними позволяет предположить, что распределения для фона и воздействия относятся к двум различным популяциям, разница между которыми обусловлена тем, что на одну из них повлияла независимая переменная.
Проверка гипотез
Как уже говорилось, задача индуктивной статистики — определять, достаточно ли велика разность между средними двух распределений для того, чтобы можно было объяснить ее действием независимой переменной, а не случайностью, связанной с малым объемом выборки (как, по-видимому, обстоит дело в случае с опытной группой нашего эксперимента).
При этом возможны две гипотезы:
1) нулевая гипотеза (H0), согласно которой разница между распределениями недостоверна; предполагается, что различие недостаточно значительно, и поэтому распределения относятся к одной и той же популяции, а независимая переменная не оказывает никакого влияния;
2) альтернативная гипотеза (H1), какой является рабочая гипотеза нашего исследования. В соответствии с этой гипотезой различия между обоими распределениями достаточно значимы и обусловлены влиянием независимой переменной.
Основной принцип метода проверки гипотез состоит в том, что выдвигается нулевая гипотеза H0, с тем чтобы попытаться опровергнуть ее и тем самым подтвердить альтернативную гипотезу H1. Действительно, если результаты статистического теста, используемого для анализа разницы между средними, окажутся таковы, что позволят отбросить H0, это будет означать, что верна H1, т. е. выдвинутая рабочая гипотеза подтверждается.
В гуманитарных науках принято считать, что нулевую гипотезу можно отвергнуть в пользу альтернативной гипотезы, если по результатам статистического теста вероятность случайного возникновения найденного различия не превышает 5 из 100 [206]. Если же этот уровень достоверности не достигается, считают, что разница вполне может быть случайной и поэтому нельзя отбросить нулевую гипотезу.
Для того чтобы судить о том, какова вероятность ошибиться, принимая или отвергая нулевую гипотезу, применяют статистические методы, соответствующие особенностям выборки.
Так, для количественных данных (см. дополнение Б.1) при распределениях, близких к нормальным, используют параметрические методы, основанные на таких показателях, как средняя и стандартное отклонение. В частности, для определения достоверности разницы средних для двух выборок применяют метод Стьюдента, а для того чтобы судить о различиях между тремя или большим числом выборок, — тест F, или дисперсионный анализ.
Если же мы имеем дело с неколичественными данными или выборки слишком малы для уверенности в том, что популяции, из которых они взяты, подчиняются нормальному распределению, тогда используют непараметрические методы — критерий ?2 (хи-квадрат) для качественных данных и критерии знаков, рангов, Манна — Уитни, Вилкоксона и др. для порядковых данных.
Кроме того, выбор статистического метода зависит от того, являются ли те выборки, средние которых сравниваются, независимыми (т. е., например, взятыми из двух разных групп испытуемых) или зависимыми (т. е. отражающими результаты одной и той же группы испытуемых до и после воздействия или после двух различных воздействий).
Дополнение Б.3. Уровни достоверности (значимости)
Тот или иной вывод с некоторой вероятностью может оказаться ошибочным, причем эта вероятность тем меньше, чем больше имеется данных для обоснования этого вывода. Таким образом, чем больше получено результатов, тем в большей степени по различиям между двумя выборками можно судить о том, что действительно имеет место в той популяции, из которой взяты эти выборки.
Однако обычно используемые выборки относительно невелики, и в этих случаях вероятность ошибки может быть значительной. В гуманитарных науках принято считать, что разница между двумя выборками отражает действительную разницу между соответствующими популяциями лишь в том случае, если вероятность ошибки для этого утверждения не превышает 5 %, т. е. имеется лишь 5 шансов из 100 ошибиться, выдвигая такое утверждение. Это так называемый уровень достоверности (уровень надежности, доверительный уровень) различия. Если этот уровень не превышен, то можно считать вероятным, что выявленная нами разница действительно отражает положение дел в популяции (отсюда еще одно название этого критерия — порог вероятности).
Для каждого статистического метода этот уровень можно узнать из таблиц распределения критических значений соответствующих критериев (t, ?2 и т. д.); в этих таблицах приведены цифры для уровней 5 % (0,05), 1 % (0,01) или еще более высоких. Если значение критерия для данного числа степеней свободы (см. дополнение Б.4) оказывается ниже критического уровня, соответствующего порогу вероятности 5 %, то нулевая гипотеза не может считаться опровергнутой, и это означает, что выявленная разница недостоверна.
Дополнение Б.4. Степени свободы
Для того чтобы свести к минимуму ошибки, в таблицах критических значений статистических критериев в общем количестве данных не учитывают те, которые можно вывести методом дедукции. Оставшиеся данные составляют так называемое число степеней свободы, т. е. то число данных из выборки, значения которых могут быть случайными.
Так, если сумма трех данных равна 8, то первые два из них могут принимать любые значения, но если они определены, то третье значение становится автоматически известным. Если, например, значение первого данного равно 3, а второго — 1, то третье может быть равным только 4. Таким образом, в такой выборке имеются только две степени свободы. В общем случае для выборки в n данных существует n — 1 степень свободы.
Если у нас имеются две независимые выборки, то число степеней свободы для первой из них составляет n1 — 1, а для второй — n2 — 1. А поскольку при определении достоверности разницы между ними опираются на анализ каждой выборки, число степеней свободы, по которому нужно будет находить критерий t в таблице, будет составлять (n1 + n2) — 2.
Если же речь идет о двух зависимых выборках, то в основе расчета лежит вычисление суммы разностей, полученных для каждой пары результатов (т. е., например, разностей между результатами до и после воздействия на одного и того же испытуемого). Поскольку одну (любую) из этих разностей можно вычислить, зная остальные разности и их сумму, число степеней свободы для определения критерия t будет равно n — 1.
Параметрические методы
Метод Стьюдента (t-тест)
Это параметрический метод, используемый для проверки гипотез о достоверности разницы средних при анализе количественных данных о популяциях с нормальным распределением и с одинаковой вариансой [207].
Метод Стьюдента различен для независимых и зависимых выборок. Независимые выборки получаются при исследовании двух различных групп испытуемых (в нашем эксперименте это контрольная и опытная группы). В случае независимых выборок для анализа разницы средних применяют формулу
t =
 ,
,
где
 — средняя первой выборки;
— средняя первой выборки;
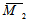 — средняя второй выборки;
— средняя второй выборки;
s1 — стандартное отклонение для первой выборки;
s2 — стандартное отклонение для второй выборки;
n1 и n2 — число элементов в первой и второй выборках.
Теперь осталось лишь найти в таблице значений t (см. дополнение Б.5) величину, соответствующую n — 2 степеням свободы, где n — общее число испытуемых в обеих выборках (см. дополнение Б.4), и сравнить эту величину с результатом расчета по формуле.
Если наш результат больше, чем значение для уровня достоверности 0,05 (вероятность 5 %), найденное в таблице, то можно отбросить нулевую гипотезу (H0) и принять альтернативную гипотезу (H1), т. е. считать разницу средних достоверной.
Если же, напротив, полученный при вычислении результат меньше, чем табличный (для n — 2 степеней свободы), то нулевую гипотезу нельзя отбросить и, следовательно, разница средних недостоверна.
В нашем эксперименте с помощью метода Стьюдента для независимых выборок можно было бы, например, проверить, существует ли достоверная разница между фоновыми уровнями (значениями, полученными до воздействия независимой переменной) для двух групп. При этом мы получим:
t =
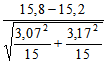 =
=
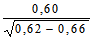 = 0,53.
= 0,53.
Сверившись с таблицей значений t, мы можем прийти к следующим выводам: полученное нами значение t = 0,53 меньше того, которое соответствует уровню достоверности 0,05 для 26 степеней свободы (? = 28); следовательно, уровень вероятности для такого t будет выше 0,05 и нулевую гипотезу нельзя отбросить; таким образом, разница между двумя выборками недостоверна, т. е. они вполне могут принадлежать к одной популяции.
Сокращенно этот вывод записывается следующим образом:
t = 0,53; ? = 28; p > 0,05; недостоверно.
Однако наиболее полезным t-тест окажется для нас при проверке гипотезы о достоверности разницы средней между результатами опытной и контрольной групп после воздействия [208]. Попробуйте сами найти для этих выборок значения и сделать соответствующие выводы:
t =
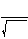 =
=
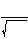 =
=
Значение t…… чем табличное для 0,05 (….. степеней свободы). Следовательно, ему соответствует порог вероятности…… чем 0,05. В связи с этим нулевая гипотеза может (не может) быть отвергнута. Разница между выборками достоверная (недостоверна?):
t =…..; ? =…..; P….. (<, =, >?) 0,05;…..
Метод Стьюдента для зависимых выборок
К зависимым выборкам относятся, например, результаты одной и той же группы испытуемых до и после воздействия независимой переменной. В нашем случае с помощью статистических методов для зависимых выборок можно проверить гипотезу о достоверности разницы между фоновым уровнем и уровнем после воздействия отдельно для опытной и для контрольной группы.
Для определения достоверности разницы средних в случае зависимых выборок применяется следующая формула:
t =
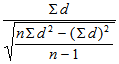 ,
,
где d — разность между результатами в каждой паре;
?d — сумма этих частных разностей;
?d2 — сумма квадратов частных разностей.
Полученные результаты сверяют с таблицей t, отыскивая в ней значения, соответствующие n — 1 степени свободы; n — это в данном случае число пар данных (см. дополнение Б.3).
Перед тем как использовать формулу, необходимо вычислить для каждой группы частные разности между результатами во всех парах, квадрат каждой из этих разностей, сумму этих разностей и сумму их квадратов [209].
Необходимо произвести следующие операции:
Контрольная группа. Сравнение результатов для фона и после воздействия
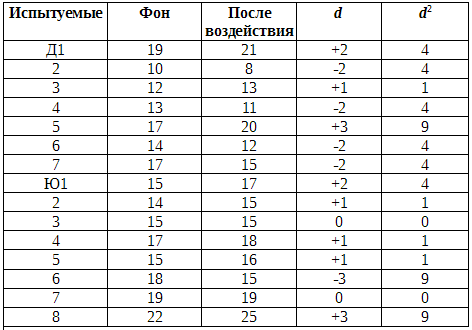
?d = +3.
?d2 = 55.
t =
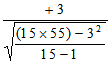 =
=
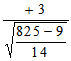 =
=
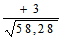 = 0,39.
= 0,39.
Величина t = 0,39 ниже той, которая необходима для уровня значимости 0,05 при 14 степенях свободы. Иными словами, порог вероятности для такого t выше 0,05. Таким образом, нулевая гипотеза не может быть отвергнута, и разница между выборками недостоверна. В сокращенном виде это записывается следующим образом:
t = 0,39; ? = 14; P > 0,05; недостоверно.
Теперь попробуйте самостоятельно применить метод Стьюдента для зависимых выборок к обоим распределениям опытной группы с учетом того, что вычисление частных разностей для пар дало следующие результаты:
?d = -59 и ?d2 = 349;
t =
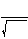 =
=
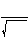 =
=
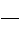 .
.
Значение t…… чем то, которое соответствует уровню значимости 0,05 для….. степеней свободы. Значит, нулевая гипотеза…… а различие между выборками…..
Запишите это в сокращенном виде.
Дисперсионный анализ (тест F Снедекора)
Метод Снедекора — это параметрический тест, используемый в тех случаях, когда имеются три или большее число выборок. Сущность этого метода заключается в том, чтобы определить, является ли разброс средних для различных выборок относительно общей средней для всей совокупности данных достоверно отличным от разброса данных относительно средней в пределах каждой выборки. Если все выборки принадлежат одной и той же популяции, то разброс между ними должен быть не больше, чем разброс данных внутри их самих.
В методе Снедекора в качестве показателя разброса используют вариансу (дисперсию). Поэтому анализ сводится к тому, чтобы сравнить вариансу распределений между выборками с вариансами в пределах каждой выборки, или:
t =…..; ? =…..; p….. (<, =, >?) 0,05; различие…..
F =
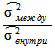 ,
,
где
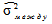 — варианса средних каждой выборки относительно общей средней;
— варианса средних каждой выборки относительно общей средней;
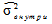 — варианса данных внутри каждой выборки.
— варианса данных внутри каждой выборки.
Если различие между выборками недостоверно, то результат должен быть близок к 1. Чем больше будет F по сравнению с 1, тем более достоверно различие.
Таким образом, дисперсионный анализ показывает, принадлежат ли выборки к одной популяции, но с его помощью нельзя выделить те выборки, которые отличаются от других. Для того чтобы определить те пары выборок, разница между которыми достоверна, следует после дисперсионного анализа применить метод Шеффе. Поскольку, однако, этот весьма ценный метод требует достаточно больших вычислений, а к нашему гипотетическому эксперименту он неприменим, мы рекомендуем читателю для ознакомления с ним обратиться к какому-либо специальному пособию по статистике.
Непараметрические методы
Метод ?2 («хи-квадрат»)
Для использования непараметрического метода ?2 не требуется вычислять среднюю или стандартное отклонение. Его преимущество состоит в том, что для применения его необходимо знать лишь зависимость распределения частот результатов от двух переменных; это позволяет выяснить, связаны они друг с другом или, наоборот, независимы. Таким образом, этот статистический метод используется для обработки качественных данных (см. дополнение Б.1). Кроме того, с его помощью можно проверить, существует ли достоверное различие между числом людей, справляющихся или нет с заданиями какого-то интеллектуального теста, и числом этих же людей, получающих при обучении высокие или низкие оценки; между числом больных, получивших новое лекарство, и числом тех, кому это лекарство помогло; и, наконец, существует ли достоверная связь между возрастом людей и их успехом или неудачей в выполнении тестов на память и т. п. Во всех подобных случаях этот тест позволяет определить число испытуемых, удовлетворяющих одному и тому же критерию для каждой из переменных.
При обработке данных нашего гипотетического эксперимента с помощью метода Стьюдента мы убедились в том, что употребление марихуаны испытуемыми из опытной группы снизило у них эффективность выполнения задания по сравнению с контрольной группой. Однако к такому же выводу можно было бы прийти с помощью другого метода — ?2. Для этого метода нет ограничений, свойственных методу Стьюдента: он может применяться и в тех случаях, когда распределение не является нормальным, а выборки невелики.
При использовании метода ?2 достаточно сравнить число испытуемых в той и другой группе, у которых снизилась результативность, и подсчитать, сколько среди них было получивших и не получивших наркотик; после этого проверяют, есть ли связь между этими двумя переменными.
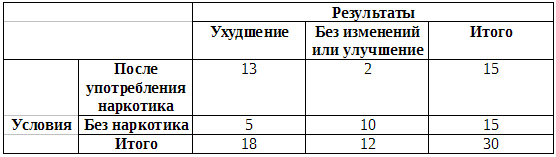
Из результатов нашего опыта, приведенных в таблице в дополнении Б.2, видно, что из 30 испытуемых, составляющих опытную и контрольную группы, у 18 результативность снизилась, а 13 из них получили марихуану. Теперь надо внести значение этих так называемых эмпирических частот (Э) в специальную таблицу:
Эмпирические частоты (Э)
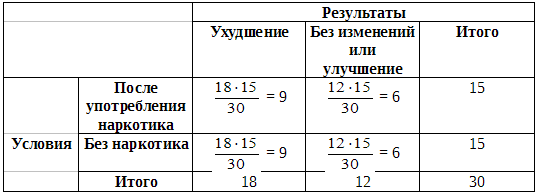
Далее надо сравнить эти данные с теоретическими частотами (Т), которые были бы получены, если бы все различия были чисто случайными. Если учитывать только итоговые данные, согласно которым, с одной стороны, у 18 испытуемых результативность снизилась, а у 12 — повысилась, а с другой — 15 из всех испытуемых курили марихуану, а 15 — нет, то теоретические частоты будут следующими:
Теоретические частоты (Т)
Метод ?2 состоит в том, что оценивают, насколько сходны между собой распределения эмпирических и теоретических частот. Если разница между ними невелика, то можно полагать, что отклонения эмпирических частот от теоретических обусловлены случайностью. Если же, напротив, эти распределения будут достаточно разными, можно будет считать, что различия между ними значимы и существует связь между действием независимой переменной и распределением эмпирических частот.
Для вычисления ?2 определяют разницу между каждой эмпирической и соответствующей теоретической частотой по формуле
 ,
,
а затем результаты, полученные по всех таких сравнениях, складывают:
?2 = ?
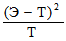 .
.
В нашем случае все это можно представить следующим образом:
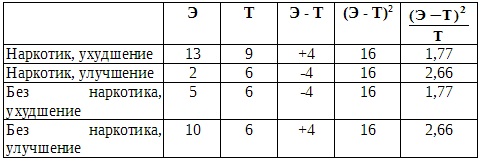
?2 = ?
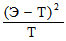 = 8,66
= 8,66
Для расчета числа степеней свободы число строк в табл. 2 (в конце приложения Б) за вычетом единицы умножают на число столбцов за вычетом единицы. Таким образом, в нашем случае число степеней свободы равно (2–1) ? (2–1) = 1.
Табличное значение ?2 (см. табл. 2 в дополнении Б.5) для уровня значимости 0,05 и 1 степени свободы составляет 3,84. Поскольку вычисленное нами значение ?2 намного больше, нулевую гипотезу можно считать опровергнутой. Значит, между употреблением наркотика и глазодвигательной координацией действительно существует связь [210].
Критерий знаков (биномиальный критерий)
Критерий знаков — это еще один непараметрический метод, позволяющий легко проверить, повлияла ли независимая переменная на выполнение задания испытуемыми. При этом методе сначала подсчитывают число испытуемых, у которых результаты снизились, а затем сравнивают его с тем числом, которого можно было ожидать на основе чистой случайности (в нашем случае вероятность случайного события 1:2). Далее определяют разницу между этими двумя числами, чтобы выяснить, насколько она достоверна.
При подсчетах результаты, свидетельствующие о повышении эффективности, берут со знаком плюс, а о снижении — со знаком минус; случаи отсутствия разницы не учитывают.
Расчет ведётся по следующей формуле:
Z =
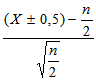 ,
,
где X — сумма «плюсов» или сумма «минусов»;
n/2 — число сдвигов в ту или в другую сторону при чистой случайности (один шанс из двух [211]);
0,5 — поправочный коэффициент, который добавляют к X, если X < n/2, или вычитают, если X > n/2.
Если мы сравним в нашем опыте результативность испытуемых до воздействия (фон) и после воздействия, то получим
Опытная группа

Итак, в 13 случаях результаты ухудшились, а в 2 — улучшились. Теперь нам остается вычислить Z для одного из этих двух значений X:
либо Z =
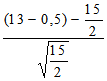 =
=
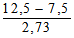 = 1,83;
= 1,83;
либо Z =
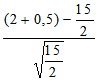 =
=
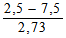 = -1,83.
= -1,83.
Из таблицы значений Z можно узнать, что Z для уровня значимости 0,05 составляет 1,64. Поскольку полученная нами величина Z оказалась выше табличной, нулевую гипотезу следует отвергнуть; значит, под действием независимой переменной глазодвигательная координация действительно ухудшилась.
Критерий знаков особенно часто используют при анализе данных, получаемых в исследованиях по парапсихологии. С помощью этого критерия легко можно сравнить, например, число так называемых телепатических или психокинетических реакций (X) (см. досье 5.1) с числом сходных реакций, которое могло быть обусловлено чистой случайностью (n/2).
Другие непараметрические критерии
Существуют и другие непараметрические критерии, позволяющие проверять гипотезы с минимальным количеством расчетов.
Критерий рангов позволяет проверить, является ли порядок следования каких-либо событий или результатов случайным, или же он связан с действием какого-то фактора, не учтенного исследователем. С помощью этого критерия можно, например, определить, случаен ли порядок чередования мужчин и женщин в очереди. В нашем опыте этот критерий позволил бы узнать, не чередуются ли плохие и хорошие результаты каждого испытуемого опытной группы после воздействия каким-то определенным образом или не приходятся ли хорошие результаты в основном на начало или конец испытаний.
При работе с этим критерием сначала выделяют такие последовательности, в которых подряд следуют значения меньше медианы, и такие, в которых подряд идут значения больше медианы. Далее по таблице распределения R (от англ. runs — последовательности) проверяют, обусловлены ли эти различные последовательности только случайностью.
При работе с порядковыми данными [212] используют такие непараметрические тесты, как тест U (Манна — Уитни) и тест T Вилкоксона. Тест U позволяет проверить, существует ли достоверная разница между двумя независимыми выборками после того, как сгруппированные данные этих выборок классифицируются и ранжируются и вычисляется сумма рангов для каждой выборки. Что же касается критерия T, то он используется для зависимых выборок и основан как на ранжировании, так и на знаке различий между каждой парой данных.
Чтобы показать применение этих критериев на примерах, потребовалось бы слишком много места. При желании читатель может подробнее ознакомиться с ними по специальным пособиям.
Корреляционный анализ
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Глава 1. Инструкция, проведение и обработка данных психографического проективного теста ТиГр
Глава 1. Инструкция, проведение и обработка данных психографического проективного теста ТиГр Инструкция для самотестирования ПРЕЖДЕ ЧЕМ ПРИСТУПИТЬ к изучению теста «КОНСТРУКТИВНЫЙ РИСУНОК ЧЕЛОВЕКА ИЗ ГЕОМЕТРИЧЕСКИХ ФОРМ™» (ТиГр – Тест Идеографический), предлагаем
Статистика — яд для ума
Статистика — яд для ума Обратимся теперь к любимой теме Канемана и Тверски, являющейся наиболее сложной для понимания и играющей существенную роль в понимании работы АКС и АС — «регрессии к среднему». Канеман описывает случай из своей практики обучения
Приложение 7 Образец сводного протокола данных тестирования на разных этапах обучения навыкам ПСР
Приложение 7 Образец сводного протокола данных тестирования на разных этапах обучения навыкам ПСР ФИО____________________ Возраст______________ Профессия/Должность________________________Стаж работы___________________ Условные обозначения: НРМ – нервно-мышечная релаксация, ИМТ – идеомоторная
Факты и статистика
Факты и статистика Сосредоточьтесь на фактах и статистических данных, чтобы убедить себя в том, что степень опасности меньше, чем
Восприятие и обработка данных
Восприятие и обработка данных ... Вы находитесь на кухне. На столе разложены продукты — мясо, овощи, зелень и т. д. Ваша задача состоит в том, чтобы обработать все это и приготовить прекрасный, незабываемый ужин. Вы принимаетесь за решение этой задачи.Наша культура
Приложение Б. Статистика и обработка данных
Приложение Б. Статистика и обработка данных ВведениеСлово «статистика» часто ассоциируется со словом «математика», и это пугает студентов, связывающих это понятие со сложными формулами, требующими высокого уровня абстрагирования.Однако, как говорит Мак-Коннелл,
Статистика
Статистика Статистика представляет собой еще одну область, где возможно прибегнуть ко лжи. Всегда можно подвести статистику под собственные желания. «Восемьдесят процентов женщин в этой стране вступают в сексуальные отношения до брака». (Так что давай займемся этим,
Статистика
Статистика Согласно данным психологов, супруги чаще всего ссорятся из-за усталости, ревности и… телевизора.Смотреть телесериал или футбол – вот в чем вопрос! И он не утрачивает своей значимости и с ростом стажа совместной
Статистика измен
Статистика измен Измены являются довольно распространенным явлением, о чем говорят многие исследования. Вот данные одного из них: 76 % мужчин в течение супружеской жизни имеют хотя бы одну внебрачную связь. У женщин такой показатель – 21 % (в Москве – 26 %). Согласно
Статистика разводов
Статистика разводов По оценке специалистов, в настоящее время в России, Украине, Беларуси распадается каждый второй брак. Десять лет назад распадался каждый третий. Рост огромный – в полтора раза!По годам семейной жизни разводы распределяются так: до 1 года – 3,6 %; от 1 до 2
Статистика
Статистика Все психологические исследования включают статистическую обработку данных. Нельзя стать исследователем в области психологии, не обладая знаниями основ статистического анализа. Кроме того, не имея элементарных представлений о том, что лежит в основе разных
ИНДИВИДУУМ И СТАТИСТИКА
ИНДИВИДУУМ И СТАТИСТИКА Для знающего – просто. Мудрость древних Достаточно часто приходится слышать вопрос, можно ли изменить человека, «переделать» его. Я всегда отвечаю, что сделать или переделать себя человек может только сам. Ему, в принципе, можно помочь, но и это
Свидетельствует статистика
Свидетельствует статистика Герберт Тру, специалист по маркетингу университета Notre Dame, выяснил, что:• 44 % всех коммивояжеров оставляют попытки после первого же звонка;• 24 % – после второго;• 14 % – после третьего.• И только 12 % продолжают пытаться продать свой товар
Сухая статистика
Сухая статистика В начале статьи мы привели несколько красочных примеров того, какие плоды приносит ЮЮ на Западе. Теперь немного сухой статистики. В Европе за последние десять лет число преступлений, совершенных несовершеннолетними, возросло на 30 %. С начала 1990–х