Интернет и мозг
Интернет и мозг
Мало кто сомневается в том, что создание глобальной компьютерной сети коренным образом изменило нашу жизнь. Влияние его на все сферы жизни современного человека поистине огромно. Если же отбросить лирику, то можно сказать, что Интернет — это всего-навсего полтора миллиарда компьютеров, разбросанных по всему свету и соединенных друг с другом различными средствами связи в единую сеть. Причем работать в Интернете настолько легко, что этому можно обучить и пятилетнего ребенка, и древнюю старушку.
Интернет обладает уникальной особенностью: несмотря на то что в его деятельность включено огромное количество компьютеров, он не имеет никакой видимой организации. В мире нет ни учреждения, ни лица, единолично ответственного за работу всей структуры. Можно сказать, что Интернет сам организуется, сам излечивается и развивается.
Создавая Интернет, люди невольно скопировали те принципы, по которым устроен человеческий мозг. Причем копирование это шло не от понимания того, как работает мозг, а от необходимости решить задачи, которые с помощью других алгоритмов не решаются.
То, с чем чаще всего сталкиваемся мы в Интернете, это служба «www» (world wide web). Службу «www» можно назвать глобальной памятью человечества. Как головной мозг хранит всю память, относящуюся к опыту одного человека, так «www» хранит информацию обо всем человечестве. Базовый элемент «www» — документ, подготовленный в специальном формате html (hyper-text meta language). Такой документ можно трактовать как одно сложное комплексное воспоминание. Доступ к этому «воспоминанию» возможен, если существуют ссылки из других документов, которые на него ведут. Посмотрите, как похоже это на организацию ассоциативной памяти, в которой каждое воспоминание тянет цепочку воспоминаний, ассоциативно с ним связанных.
Немаловажную роль в функционировании Интернета играют поисковые серверы.
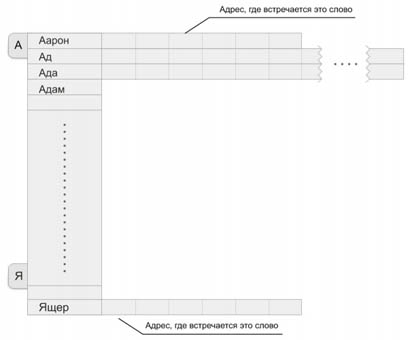
Рисунок 23. Схема организации поискового сервера.
Поисковый сервер содержит перечень слов того языка, на котором он позволяет осуществлять поиск. С каждым словом связан список документов (адресов), в которых встречается конкретное слово. Когда мы вводим запрос, состоящий из нескольких слов, нам выдается перечень документов, в которых присутствуют искомые слова.
Чтобы почувствовать сходство организации Интернета и головного мозга, скажем то же самое несколько другими словами. Среда Интернета в совокупности представляет собой память. Эта память организована ассоциативно, роль ассоциативных связей выполняют гиперссылки (ссылки из одного документа на
другой) и поисковые серверы (связи между словами и документами). Интеграция новой информации в Интернете, как и в головном мозге, происходит на базе уже существующих понятий. Это — слова, известные поисковым машинам, и существующие документы. По мере развития Интернета документы «обрастают» дополнительными ассоциативными связями. Так, постоянно расширяется количество ассоциаций у слов в поисковиках или же количество ссылок, ведущих к какой-то важной и полезной информации.
Особенно хочется обратить внимание на то, что и Интернет, и мозг в силу схожести своей организации приобретают и схожие свойства. Информация в обоих случаях пространственно распределена, то есть ассоциативно связанные понятия могут пространственно находиться далеко друг от друга. Сходна и устойчивость к повреждениям: пропадание какого-либо элемента не приводит к полной потере информации, а ведет лишь к некоторому ее «обеднению».
Конечно, не надо отождествлять Интернет и мозг. Из общих принципов, лежащих в организации ассоциативной памяти, следует много совпадающих свойств, можно проводить интересные параллели, но не следует забывать о том, что это все же — два разных явления.
В то же время к одной из «параллелей» относится сравнение текущего представления у человека и картина активности Интернета (напомним: текущее представление — это набор активных понятий внутреннего языка, определяющий то, о чем человек «думает» в данный момент).
Поскольку текущее представление присутствует в конструкции ассоциативной памяти, то оно уже содержит в себе информацию о том, «в какую сторону пойдет мысль», поскольку память определяет вероятность тех или иных ассоциативных переходов. В Интернете в каждый конкретный момент можно говорить о «текущем представлении Интернета»,— если зафиксировать информацию о том, сколько человек в этот момент просматривают тот или иной документ. Такая картина косвенно говорит о том, что «волнует» пользователей Интернета. Например, какая-либо яркая новость привлекает к себе большое количество читателей. С высокой вероятностью можно сказать, что люди, заинтересовавшиеся этой новостью, перейдут по ссылкам, ассоциативно с ней связанным, или будут искать в поисковиках информацию, связанную с тем, к чему относится новость. Эта новость будет перепечатана множеством серверов, и какое-то время все, что связано с ней, будет людям интересно, а вокруг этой информации будет наблюдаться активность. По прошествии времени интерес людей переключится на другие события, активность этой новости упадет до нуля. Однако она останется как часть «памяти» Интернета, связанная ссылками со множеством других документов. Иногда кто-то будет к ней возвращаться и мы сможем наблюдать незначительную активность. Но не исключено, что произойдет некое событие, которое заставит вернуться к старой новости многих, и информация опять станет актуальной. Все это сильно напоминает изменение текущего представления у человека.
Итак, Интернет — «память человечества», а поисковые системы позволяют получить доступ к «воспоминаниям». В чем недостаток существующих поисковых систем? Почему, введя осмысленный вопрос, мы далеко не всегда получаем осмысленный ответ? Дело в том, что воспоминания, которыми оперирует мозг,— это фиксация текущего представления, которое соответствовало моменту запоминания. Такое воспоминание содержит в себе «смысл» информации. Документы же, размещенные в Интернете,— это документы на естественном языке, а естественный язык — это только способ передачи информации. И, как я уже говорил выше, смысл возникает только в сочетании с памятью человека. Установление связей документа и слов в поисковой машине — не то же самое, что формирование ассоциативных связей у человека.
Интересно обратить внимание на то, что в поисках способов для оптимизации работы поисковых систем идет воссоздание тех алгоритмов, которые присущи человеческому мозгу. Так, поскольку смысл текста, размещенного в Интернете, в очень слабой степени определяется набором входящих в него слов, используются «мета-теги». Это — набор идущих через запятую слов, который задается авторами страницы и который должен дать поисковой системе представление о смысле текста.
Уже давно идут разработки «семантического веба».
В 1991 г. Тим Бернерс-Ли создал Интернет и этим навсегда изменил характер взаимного общения людей. Спустя несколько лет он начал рассуждать о своем новом видении «паутины», которая сможет делать с данными то же самое, что обычный Интернет уже сделал с неструктурированным контентом.
Бернерс-Ли называет это «семантическим вебом». Говоря упрощенно, семантический веб позволит рассматривать Интернет в целом как базу данных (БД). Точно так же, как разработчик может запрашивать сведения из обычной БД и создавать приложения, оперирующие этой информацией, любой человек получит возможность собирать данные во всей интернет-сети и в соответствии со своими нуждами строить приложения, обрабатывающие взаимосвязанные, но разрозненные сведения из различных источников.
В семантическом вебе не нужно вдаваться в подробности, о чем именно идет речь в том или ином конкретном случае, запуская для этого поиск фрагментов текста и выдвигая собственные предположения, поскольку информация в этом случае будет соответствующим образом размечаться и снабжаться четкими указаниями. Но еще важнее, что к семантическому вебу можно будет легко подключиться, чтобы найти однотипные или взаимосвязанные данные (Рапоза, 2007).
Идея семантического веба заключается в том, чтобы представить каждый документ или файл в Интернете в виде некоего «воспоминания» со своим уникальным идентификатором URI.
URI — это унифицированные идентификаторы ресурсов (Uniform Resource Identifier). «Всякий раз, когда вы заходите в Интернет, вы используете множество URI, поскольку это основной метод адресации в Сети. (Любой стандартный веб-адрес в формате URL представляет собой один из видов URI). URI имеют большое значение для семантического веба, потому что для доступа к данным необходимо иметь возможность указать место их размещения и идентифицировать их точно так же, как в случае с веб-сайтом... » (Рапоза, 2007).
Далее задача заключается в том, чтобы увязать каждый объект с другими через создание связей различного типа. Такие связи позволяют дать «смысловое» описание объекта.
Первый стандарт, разработанный в рамках семантического веба, призванный дать возможность описывать объекты, называется RDF (Resource Description Framework). RDF позволяет описать размещенный в Интернете контент таким образом, чтобы сделать его «<понятным» для машины... (Рапоза, 2007).
Видно, что идеи семантической паутины все больше и больше приближают устройство Интернета к устройству мозга. У разработчиков WEB 3.0 (так принято называть семантический веб) велико желание создать четкую, непротиворечивую конструкцию. Однако это желание натыкается на то, что в большинстве случаев информация, создаваемая людьми, не является детерминированной, то есть не позволяет со стопроцентной вероятностью гарантировать «правильное» понимание, и более того, может являться ложной или двусмысленной. Это накладывает определенные ограничения и требует дополнительных идей и решений.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Женский мозг, мужской мозг
Женский мозг, мужской мозг Женский и мужской мозг — разные. Однако недавние исследования показывают, насколько ошибочно предполагать, что все гендерные различия запрограммированы. По всему миру психологи и неврологи бьются над старым, как мир, вопросом: «Почему женщина
Интернет
Интернет Не только телевидение собирает под свои знамена сонмы придурков. Этим с успехом справляется Интернет.Всевозможные социальные сети, вроде «В Контакте», «Одноклассники» и прочие, вбирают в себя массу народа, там нет живого общения, редко встретишь что-то разумное
Древний мозг и новый мозг
Древний мозг и новый мозг Посмотрим внимательнее, как устроен мозг. Рисунок 2. Строение мозга человекаОбозначения: 1. Борозда мозолистого тела. 2. Угловая борозда. 3. Угловая извилина. 4. Мозолистое тело. 5. Центральная борозда. 6. Парацентральная долька. 7. Предклинье. 8.
«Левый мозг»/«правый мозг»
«Левый мозг»/«правый мозг» Более 100 лет нам было известно, что два полушария головного мозга человека выполняют различные функции. Травмы, инсульты и опухоли левого полушария обычно влияли на функции рационального, вербального, неинтуитивного разума, такие как чтение,
ИНТЕРНЕТ
ИНТЕРНЕТ Вы действительно застенчивы? Боитесь говорить с мужчинами? Боитесь оказаться уязвимой или что вас могут обидеть? Ну конечно, боитесь. Нет проблем: есть место, где можно практиковаться в искусстве флирта и оттачивать свой стиль, где любой отказ кажется неважным, а
Правый мозг, левый мозг
Правый мозг, левый мозг Если взглянуть на схематическое изображение мозга человека, то нетрудно заметить, что одним из самых крупных образований головного мозга являются симметрично расположенные большие полушария – правое и левое. Несмотря на то, что по
Левый мозг, правый мозг: введение
Левый мозг, правый мозг: введение Вы знаете, что наш мозг разделен на два полушария. Эти две части мозга не только разделены анатомически, они, кроме того, выполняют разные функции. Некоторые даже полагают, что два полушария обладают каждое своей собственной личностью или
Социальный мозг: мозг включает понятие «Мы»
Социальный мозг: мозг включает понятие «Мы» Что вы представляете себе, когда думаете о мозге? Возможно, вам вспоминается некий образ из школьного курса биологии: странный орган, плавающий в банке, или картинка в учебнике. Такое восприятие, когда мы рассматриваем
ИНТЕРНЕТ
ИНТЕРНЕТ Есть очень хороший и верный способ найти престижную работу. Это Интернет. Для этого вам совсем не обязательно быть завзятым хакером и разбираться в компьютере, как женщина в косметике. Достаточно лишь знать, куда обратиться.Это, пожалуй, самое эффективное
Интернет
Интернет — Пока не воспользовался интернетом, не знал, что на свете есть столько идиотов. Приписывается разным именитым писателям. — Насколько я знаю, интернет всего лишь еще один способ быть отвергнутым женщиной, «Вам письмо» (фильм) Интернет — с одной стороны зло, с
Интернет
Интернет Развитие широкополосного интернета почти полностью погубило пикап-движение в России. Мое грустное наблюдение. Тут все совсем просто. Интернет — это великая свалка, где много всего и сразу. Для нормального серфинга хватает нормального файрвола который рубит
Глава 8 Пойманные паутиной, или Наш мозг и интернет
Глава 8 Пойманные паутиной, или Наш мозг и интернет Все началось с кричавшего человека в толпе. Почему он кричит? Кто-то сказал «бомба»? В секунду возникла массовая давка. Это была памятная церемония, посвященная Второй мировой войне, в Амстердаме в мае 2010 года. Одна
Глава 5 Занятой мозг – умный мозг?
Глава 5 Занятой мозг – умный мозг? Как вы усваиваете новое и каким образом оптимизировать этот процесс Джесси приходилось учить и усваивать много нового. В мире медицины учиться приходится постоянно.И Джесси училась, сколько себя помнит. Однако с тех пор, как она