Печенье в форме животных
Способность объектов притягивать к себе системы координат помогает разрешить одну из главных проблем зрения – следующую проблему, с которой мы сталкиваемся на трудном пути от сетчатки к абстрактной мысли. Как люди распознают формы? Среднестатистический взрослый знает названия примерно 10 000 вещей и большинство из них он различает по форме. Даже шестилетний ребенок знает названия нескольких тысяч вещей, которые он выучивает в течение нескольких лет, по одному слову каждые несколько часов. Конечно, предметы можно распознать по многим подсказкам. Некоторые из них можно узнать по звукам и запахам, другие – например, рубашки в корзине со стиркой – только по цвету и материалу. Однако большинство предметов можно узнать по форме. Распознавая форму предмета, мы действуем как геометры, наблюдая расположение вещества в пространстве и находя наиболее близкое соответствие наблюдаемому в своей памяти. Наш ментальный геометр обладает, по-видимому, необыкновенной проницательностью, потому что даже трехлетний ребенок может, перебирая печенье в виде животных или формочки из разноцветной пластмассы, не задумываясь называть редких представителей фауны по одному только их контуру.
Схема в нижней части страницы 19 наглядно демонстрировала, почему эта проблема представляет такую сложность. Когда предмет или наблюдатель двигается, контуры 2,5-мерного эскиза меняются. Если ваше воспоминание о той или иной форме – скажем, форме чемодана – было копией 2,5-мерного эскиза этого предмета в том виде, в котором вы его увидели впервые, то сдвинутая с места версия уже не будет ему соответствовать. Ваше воспоминание о чемодане было таким: «прямоугольный блок и горизонтальная ручка в положении на 12 часов», однако теперь ручка, на которую вы смотрите, расположена не на 12 часов и не горизонтально. Вам остается бессмысленно уставиться на стоящий перед вами предмет, не понимая, что это.
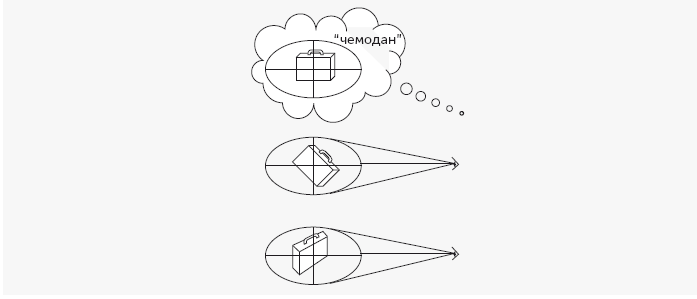
Теперь представим, что вместо системы координат, привязанной к сетчатке, ваша память использует систему координат, выровненную по самому предмету. Ваше воспоминание будет примерно таким: «прямоугольный блок с ручкой, расположенной параллельно краю блока, в верхней части блока». Часть формулировки, выделенная курсивом, указывает на то, что вы запоминаете расположение частей относительно самого предмета, а не относительно поля зрения. В дальнейшем, когда вы увидите неопознанный объект, ваша зрительная система автоматически выровняет трехмерную систему координат по этому объекту, как это было в случае с ансамблями квадратов и треугольников в примере Этнива. Теперь, когда вы можете соотнести то, что вы видите, с тем, что вы помните, первое и второе всегда совпадет, независимо от того, как повернут чемодан, и вы безошибочно узнаете свой багаж.
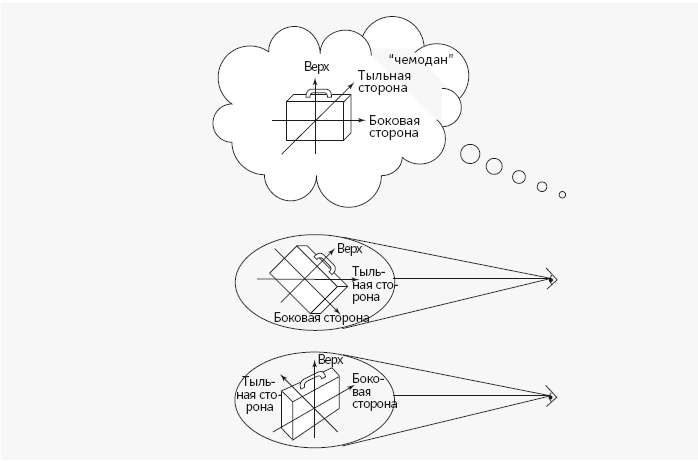
Так в общих чертах объясняет распознавание формы Марр. Основная идея заключается в том, что воспоминание о форме – это не копия 2,5-мерного эскиза; оно хранится в формате, который отличается от такой копии по крайней мере в двух отношениях. Во-первых, начало этой системы координат совпадает с предметом – а не с наблюдателем, как в 2,5-мерном эскизе. Чтобы распознать предмет, мозг выравнивает систему координат по осям растяжения и симметрии и измеряет координаты и углы отдельных частей в этой системе отсчета. Только тогда видимый предмет и воспоминание о нем совпадают. Второе различие заключается в том, что механизм сопоставления не сравнивает видимый предмет и воспоминание пиксель за пикселем, словно собирая пазл. Если бы это было так, формы, которые должны совпадать, могли бы и не совпасть. У реальных предметов есть выступы и углубления, они бывают разных стилей и моделей. Нельзя найти два чемодана с абсолютно одинаковыми размерами; у некоторых чемоданов закругленные углы, у одних ручки тонкие, у других толстые. Поэтому репрезентация формы, которой подбирается соответствие, не должна в точности воспроизводить каждый бугорок и каждую впадинку. Она должна формулироваться с помощью обтекаемых категорий – таких, как «блок» или «U-образный элемент». Расположение деталей тоже не должно указываться с точностью до миллиметра – у всех кружек ручки «сбоку», но у разных ручек они могут располагаться на разной высоте[281].
Психолог Ирв Бидерман конкретизировал две идеи Марра с помощью набора простых геометрических деталей, которые он назвал «геонами» (по аналогии с протонами и электронами, составляющими атом)[282]. Вот пять таких геонов и некоторые варианты их комбинаций:
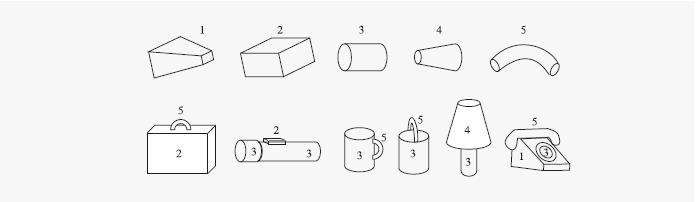
Бидерман предлагает в общей сложности 24 геона, в числе которых – конус, мегафон, футбольный мяч, труба, куб, короткая макаронина-«рожок». (Технически это просто разные варианты конусов. Если рожок мороженого – это поверхность, образуемая расширяющимся кругом, центр которого двигается вдоль прямой линии, то геоны – это поверхности, образуемые другими двухмерными формами, расширяющимися или сужающимися по мере движения вдоль прямой или кривой линии.) Геоны могут комбинироваться, образуя предметы, с помощью немногочисленных типов соединения, обозначаемых как «вверху», «сбоку», «встык», «параллельно». Эти отношения определяются в системе координат, начало которой совпадает, конечно же, с предметом, а не с полем зрения; «вверху» означает «над основным геоном», а не «над центральной ямкой сетчатки». Таким образом, отношения остаются неизменными, когда предмет или наблюдатель перемещается.
Геоны комбинаторны, как грамматика. Очевидно, что мы мысленно не описываем формы словами, однако комбинации геонов – это что-то вроде внутреннего языка, диалект мыслекода. Элементы фиксированного словарного запаса встраиваются в более крупные структуры подобно тому, как слова встраиваются в словосочетание или предложение. Предложение – не просто сумма входящих в него слов; его значение зависит от их синтаксического расположения; «Человек кусает собаку» не то же самое, что «Собака кусает человека». Подобным образом, объект не является просто суммой входящих в него геонов, а зависит от их пространственного расположения; цилиндр с «рожком» сбоку— это кружка, а цилиндр с «рожком» сверху— это ведро. И точно также, как из малого количества слов и правил комбинируется астрономическое количество предложений, из малого количества геонов и типов их соединений комбинируется астрономическое количество предметов. По Бидерману, каждый из 24 геонов бывает 15 размеров и степеней толщины, существует 81 способ их соединения. Это позволяет создать из двух геонов 10497600 предметов, из трех геонов – 306 миллиардов предметов. Теоретически этого должно быть более чем достаточно, чтобы покрыть все десятки тысяч известных нам форм. На практике оказывается, что сконструировать легко узнаваемые модели знакомых нам предметов можно из трех, а иногда и всего из двух геонов.
Язык и сложные формы вообще, похоже, соседствуют в мозге. Левое полушарие отвечает не только за язык, но и за способность распознавать и представлять в уме формы, определяемые взаимным расположением частей. Неврологический больной, перенесший инсульт в правом полушарии мозга, рассказывал: «Когда я пытаюсь представить растение, животное, предмет, у меня получается вспомнить только одну часть. Мое внутреннее зрение неустойчиво и фрагментарно; если меня просят представить голову коровы, я знаю, что у нее есть уши и рога, но не могу восстановить в воображении их расположение». Правое полушарие, напротив, используется для измерения форм целиком; оно с легкостью может оценить, превышает ли высота прямоугольника его ширину, или располагается ли точка на расстоянии трех или пяти сантиметров от предмета[283].
Одно из преимуществ теории геонов заключается в том, что она предъявляет оправданные требования к 2,5-мерному эскизу. Расчленить предметы на части, идентифицировать каждую часть как тот или иной геон и определить их взаимное расположение – все это вполне решаемые задачи, и специалисты по исследованию зрения уже разработали модели того, каким образом мозг их может решать. Еще одно преимущество – в том, что описание анатомии предмета помогает мозгу думать о предметах, а не просто выдавать их названия. Люди понимают, как устроены предметы и для чего они нужны, анализируя форму и расположение их частей[284].
Теория геонов утверждает, что на высших уровнях восприятия наш разум «видит» предметы и их части как идеализированные геометрические тела. Это объясняет любопытный и давно подмеченный факт, касающийся эстетики визуального восприятия. Любой, кто когда-либо был на занятии по рисованию человека с натуры или на нудистском пляже, быстро усваивает, что в реальной жизни человеческие тела не соответствуют нашим идеальным представлениям. Большинство из нас выглядит гораздо лучше в одежде. В своей работе по истории моды историк искусства Квентин Белл дает объяснение, которое словно непосредственно вытекает из теории геонов:
Если завернуть предмет в какую-либо оболочку, чтобы можно было скорее предполагать, а не видеть, что за предмет в нее завернут, предполагаемая или воображаемая форма скорее будет идеальной, чем если бы она была открыта для глаз. Так, квадратная коробка, накрытая коричневой бумагой, будет представляться нам идеально квадратной. Если только мышлению не дать какую-нибудь явную подсказку, оно вряд ли представит отверстия, углубления, трещины или другие случайные признаки. Точно так же, если мы набросим драпировку на бедро, ногу, руку или грудь, воображение предположит часть тела идеальной формы; оно не предусматривает и обычно и не может предусмотреть неровности и несовершенства, которых нам следовало бы ожидать, исходя из опыта…Мы знаем, как может выглядеть [тело], по опыту и все же готовы отмести свое недоверие, предпочитая фикцию, создаваемую гардеробом [человека]. Более того, я полагаю, что мы готовы идти еще дальше по пути самообмана. Когда мы надеваем свой лучший пиджак и видим, что наши прискорбно невпечатляющие плечи от этого увеличиваются и приобретают идеальную форму, у нас и в самом деле на мгновение повышается самооценка[285].
Геоны подходят не для всего. Многие природные объекты— такие, как деревья и горы – обладают сложной фрактальной формой, а геоны превращают их в пирамиды и леденцы на палочке. И хотя из геонов можно построить довольно приемлемые очертания человеческого лица, напоминающие снеговика или игрушку вроде Мистера Картофеля, из них практически невозможно построить модель конкретного лица (лица Джона, лица вашей бабушки) так, чтобы оно отличалось от всех остальных лиц в достаточной степени, чтобы их нельзя было спутать, и в то же время всегда оставалось собой, позволяя всегда безошибочно идентифицировать данного человека, когда он хмурится, улыбается, полнеет, стареет. Многие психологи считают, что способность распознавать лица уникальна. Для общественного животного, которым является человек, лица так важны, что естественный отбор снабдил нас специальным устройством обработки информации, которое регистрирует разные геометрические контуры и коэффициенты, необходимые, чтобы отличать лица друг от друга. Младенец уже в возрасте получаса от роду фиксирует взгляд на контурах, похожих на лицо (такого эффекта на него не производит никакой иной сложный и симметричный контур), и быстро учится узнавать мать – вероятно, уже на второй день жизни[286].
Механизм распознавания лица, возможно, задействует и более удаленные области мозга. Неспособность различать лица носит название «прозопагнозия». Это не тот же самый недуг, что и у человека, принявшего жену за шляпу в рассказе Оливера Сакса: прозопагностик отличает лицо от шляпы; он просто не может сказать, чье это лицо. Тем не менее многие из таких пациентов распознают шляпы и почти все остальные предметы. Так, психологи Нэнси Эткофф и Кайл Кев, а также невролог Рой Фриман описывают случай одного из таких пациентов, некоего Л. Г. – умного, образованного человека, который двадцатью годами ранее получил травму головы в результате автомобильной аварии. После аварии он полностью утратил способность узнавать лица. Он не узнает жену и детей (только по голосу, запаху и походке), собственное лицо в зеркале, знаменитых людей на фотографиях (за исключением лиц с особенно запоминающимися особенностями – Эйнштейна, Гитлера, молодых «Битлз» с их пышными прическами). Не то чтобы он не различал детали лица; он легко соотносил изображения лиц анфас с изображениями в профиль, причем даже при специфическом художественном освещении, определял их возраст и пол, оценивал привлекательность. Он практически без затруднений распознавал иные сложные предметы: слова, одежду, прически, транспорт, инструменты, овощи, музыкальные инструменты, офисную мебель, очки, узоры из точек, фигуры наподобие телевизионной антенны. Проблемы у него вызывали только два вида фигур. К его большому смущению, он не мог назвать животных, изображенных на детских крекерах; в ходе лабораторного эксперимента он также показал результаты ниже среднего, когда его попросили назвать животных, изображенных на рисунках. Кроме того, ему было сложно узнать выражение лица – хмурый взгляд, усмешку, угрожающую гримасу. Однако ни животные, ни выражения лиц не вызывали у него таких трудностей, как различение лиц, к которому он был вообще неспособен[287].
Нельзя сказать, что лица – это самое сложное, что когда-либо приходилось распознавать нашему мозгу, и если мозг не работает на полную мощность, то первой пострадает именно способность распознавать лица. Психологи Марлин Берманн, Моррис Москович и Гордон Винокур описывают молодого пациента, которого ударило по голове зеркало заднего вида проезжавшего мимо грузовика. Он испытывает трудности в распознавании предметов обихода, но без труда узнает лица, даже если их изменить с помощью очков, парика или накладных усов. Его синдром – противоположность прозопагнозии, и он подтверждает тот факт, что распознавание лиц не сложнее распознавания предметов, это просто другой механизм[288].
Получается, что у прозопагностиков просто выходит из строя модуль распознавания лиц? Некоторые психологи, отмечая, что Л. Г. и другие прозопагностики испытывают трудности и с узнаванием некоторых других форм, утверждают, что у таких пациентов нарушена способность обрабатывать те виды геометрических характеристик, которые имеют наибольшее значение для распознавания лица, но также нужны и для узнавания некоторых других разновидностей форм. Мне представляется, что проводить различие между узнаванием лиц и узнаванием предметов с геометрическими параметрами лица бессмысленно. С точки зрения мозга никакой предмет не является лицом, если только он не опознан как лицо. Единственное, чем может отличаться от других конкретный модуль восприятия, – это то, на какие геометрические параметры он обращает внимание – например, на расстояние между симметричными выпуклостями или на линии изгибов двухмерных эластичных поверхностей, натянутых поверх трехмерного каркаса и подчеркнутых подложенными под них мягкими вставками и связками. Если какие-то объекты помимо лиц (а это животные, выражения лица и даже автомобили) обладают некоторыми из этих геометрических особенностей, у модуля не будет иного выбора кроме как анализировать их, даже если наибольшее значение такие особенности имеют именно для лиц. Называть модуль модулем распознавания лиц не означает утверждать, что он обрабатывает только лица; это означает, что он оптимизирован для работы с геометрическими параметрами, которые позволяют различать лица, потому что способность нашего организма их распознавать была отобрана в процессе эволюции.
* * *
Теория геонов привлекательна, но верна ли она? Уж конечно не в чистом виде, в котором каждому объекту должно соответствовать одно описание его трехмерной геометрии, не осложненное искажениями из-за изменения точки наблюдения. Большинство предметов непрозрачны, и некоторые их поверхности закрывают собой другие. В связи с этим в буквальном смысле невозможно получить одно и то же описание объекта при восприятии с разных точек обзора. Например, вы не можете знать, как выглядит тыльная сторона дома, если стоите перед его фасадом. Марр обошел эту проблему, вообще игнорируя поверхности и анализируя формы животных так, словно они сделаны из каркасной проволоки. Версия Бидермана учитывает эту проблему, отводя каждому предмету несколько геонных моделей в ментальном каталоге – по одному для каждого из видов, необходимых, чтобы показать все поверхности предмета.
Тем не менее эта уступка открывает возможности для совершенно новой интерпретации процесса распознавания формы. Почему бы не довести эту идею до логического конца и не снабдить каждую форму большим количеством файлов в памяти, по одному для каждой точки обзора? Тогда этим файлам не понадобится хитроумная система координат с предметом в качестве исходной точки; вместо этого можно будет использовать координатную систему сетчатки, прилагающуюся к 2,5-мерному эскизу, при условии, что в нашем распоряжении будет достаточно файлов для всех углов обзора. В течение многих лет эту идею без дальнейших раздумий отвергали. Если весь диапазон углов обзора разбить на сектора в один градус, для одного предмета потребуется сорок тысяч файлов, чтобы охватить их все (и речь идет о том, чтобы охватить только все углы обзора; в расчет не принимаются разные позиции наблюдения, при которых предмет оказывается не прямо по центру, и разные расстояния от наблюдателя до предмета). Экономить, выбирая только несколько видов (подобно тому, как архитектор разрабатывает план и фасад здания), нельзя: теоретически любой из видов может оказаться критически важным. (Элементарное доказательство: представьте себе предмет в виде пустотелой сферы, внутри которой приклеена игрушка, напротив которой просверлено маленькое отверстие. Только в том случае, если через отверстие видна игрушка, мы можем говорить о том, что виден весь предмет целиком.) Тем не менее в последнее время идея приобрела популярность. Если разумно подходить к выбору нужных видов и использовать ассоциатор паттернов для перехода между ними в тех случаях, когда предмет не совпадает с первым же видом, можно сократить количество видов каждого предмета до такого, которым без проблем можно оперировать, – максимум до сорока[289].
Даже в этом случае кажется маловероятным, чтобы людям для последующего распознавания объекта было необходимо увидеть его с сорока разных точек зрения, однако здесь имеется еще одна хитрость. Напомним, что люди, интерпретируя формы, ориентируются на вертикальную ось: квадрат – не то же самое, что ромб; повернутый на бок контур Африки – уже не Африка. С этим связано еще одно усложнение чистой теории геонов: такие соотношения, как «над» и «наверху», должны быть привязаны к положению сетчатки (с некоторой поправкой на гравитацию), а не к предмету. Эта оговорка практически неизбежна, потому что зачастую мы можем указать «верх» объекта только тогда, когда объект распознан. И все же главная трудность связана с тем, что делают люди с повернутым на бок объектом, который они не распознали сразу. Если человеку сказать, что фигура повернута на бок, он ее быстро узнает – скорее всего, так было и с вами, когда я сказал вам, что изображение Африки повернуто на бок. Люди могут мысленно повернуть фигуру, поставив ее вертикально, а затем распознать повернутое изображение. Учитывая, что у нас в распоряжении есть этот механизм вращения ментальных образов, предлагаемая теорией геонов система отсчета, ориентированная на предмет, становится тем более ненужной. Человек в этом случае мог бы хранить несколько 2,5-мерных видов с нескольких стандартных точек обзора – как фото арестованного в полицейском участке – а если наблюдаемый объект не совпадает ни с одним из снимков, мысленно поворачивать его, пока не будет найдено соответствие. Подобное сочетание нескольких видов и мысленного вращения сделало бы геонную модель в системе координат, привязанной к предмету, ненужной[290].
* * *
Если у нас есть столько вариантов процесса распознавания формы, как определить, какой из них соответствует реальным процессам нашего мышления? Единственный способ узнать это – наблюдать за тем, как человек распознает формы, в экспериментальных условиях. Одна широко известная серия таких экспериментов указывает на то, что ключевую роль играет мысленное вращение. Психологи Линн Купер и Роджер Шепард показывали людям буквы алфавита в разных положениях – в вертикальном положении, с наклоном в 45°, лежащие на боку, повернутые на 135°, вверх ногами. Купер и Шепард не просили людей просто называть букву вслух, потому что боялись упростить задачу: в этом случае какая-нибудь характерная черта буквы вроде петельки или хвостика, идентифицируемая в любом положении, могла выдать правильный ответ. Они вынуждали испытуемых анализировать все геометрические параметры каждой буквы, показывая либо саму букву, либо ее отражение в зеркале. Испытуемому предлагали нажимать на одну кнопку, если он видел нормальную букву, и другую кнопку, если перед ним было ее зеркальное отражение.
Когда Купер и Шепард измерили время, требующееся испытуемым, чтобы нажать на кнопку, они заметили явный признак мысленного вращения. Чем больше буква была отклонена от вертикального положения, тем больше времени требовалось испытуемому. Именно такого результата следовало бы ожидать, если бы люди постепенно поворачивали изображение буквы, приводя его к вертикальному; чем больше его нужно поворачивать, тем дольше занимает операция поворота. Следовательно, вполне вероятно, что люди распознают формы, мысленно поворачивая их[291].
С другой стороны, это может быть и не так. Люди ведь не просто распознавали формы; они отличали их от зеркальных отражений. Изображения в зеркале – вещь особая. Не зря ведь продолжение «Алисы в Стране чудес» получило название «Алиса в Зазеркалье». Соотношение между фигурой и ее отражением в зеркале всегда было источником удивительных открытий и даже парадоксов во многих отраслях науки. (Этим удивительным фактам посвящены занимательные книги Мартина Гарднера, а также Майкла Корбаллиса и Айвана Беале.) Представьте, что перед вами правая и левая руки манекена, отделенные от туловища. В каком-то смысле они идентичны друг другу: на каждой из них пять пальцев, присоединенные к ладони и запястью. В другом смысле они совершенно различны; контур одной нельзя наложить поверх контура другой. Различие заключается только в том, как части выровнены относительно системы координат, в которой все три оси соответствуют направлениям «вверх— вниз», «вперед – назад», «влево – вправо». Когда правая рука направлена пальцами вверх и ладонью вперед (как будто изображая жест «стоп»), большой палец направлен влево; когда левая рука направлена пальцами вверх и ладонью вперед, большой палец направлен вправо. Это единственное различие, но оно реально. Молекулы жизни имеют направленность; их зеркальные отражения в природе не существуют и не могут функционировать в телах.
Принципиальным открытием физики XX века стало открытие, что Вселенная тоже имеет направленность. На первый взгляд это кажется абсурдом. Какой бы предмет или событие в космосе мы ни взяли, мы никак не можем знать, видим ли мы само событие или его зеркальное отражение. Вы можете возразить, что есть исключения – молекулы органических соединений и объекты искусственного происхождения (например, буквы алфавита). Их стандартные версии широко распространены и знакомы всем; их зеркальные отображения встречаются редко и их легко узнать. Тем не менее с точки зрения физика это неудачный пример, потому что их направленность – историческая случайность, а не нечто предопределенное законами физики. На любой другой планете (или даже на этой, если бы мы могли перемотать назад пленку эволюции и заставить ее повториться заново) они могли бы с такой же легкостью оказаться направленными в другую сторону. До недавнего времени физики считали, что это верно для всех объектов во Вселенной. Вольфганг Паули писал: «Я не верю, что Бог – слабый левша»; Ричард Фейнман готов был поставить пятьдесят долларов к одному (сотню поставить он не решился), что ни один эксперимент никогда не выявит закона природы, который бы выглядел иначе в зеркальном отражении. Он проиграл. Говорят, что ядро атома кобальта-60 вращается против часовой стрелки, если смотреть на его северный полюс, однако самое это описание по себе представляет собой порочный круг, поскольку «северный полюс» – это словосочетание, которое мы используем для окончания оси, с точки зрения которого вращение кажется нам направленным против часовой стрелки. Этот логический круг можно было бы разорвать, если бы что-то другое помогало отличить так называемый северный полюс от так называемого южного полюса. А вот и это «что-то другое»: когда атом распадается, электроны с большей степенью вероятности будут выбрасываться с того конца, который мы называем южным. «Север» как противопоставление «югу» и движение «по часовой стрелке» как противопоставленное движению «против часовой стрелки» при этом перестают быть произвольно выбранными ярлыками, а могут различаться относительно направления выброса электронов. Распад атома – а следовательно, и вся Вселенная – будет выглядеть иначе в зеркальном отражении. Получается, что Бог вовсе не амбидекстер[292].
Итак, право- и левосторонние версии вещей, от субатомных частиц до живой материи и до вращения Земли, коренным образом различаются. Однако разум обычно воспринимает их так, как если бы они были одинаковыми:
Пух посмотрел на свои передние лапки. Он знал, что одна из них была правая, знал он, кроме того, что если он решит, какая из них правая, то остальная будет левая. Но он никак не мог вспомнить, с чего надо начать[293].
У нас тоже не лучше Винни-Пуха получается определить, с чего начать. Левый и правый ботинок выглядят так похоже, что детей приходится специально обучать особым хитростям, чтобы различить их – например, поставить ботинки рядом и измерить расстояние между носами. В какую сторону смотрит Авраам Линкольн на одноцентовой монете? Вероятность, что вы ответите правильно – всего пятьдесят процентов, как если бы вы выбирали ответ, подкинув монетку. А как насчет знаменитой картины Уистлера «Аранжировка в сером и черном. Мать художника»? Даже в английском языке сталкиваются левое и правое: есть слова beside и next, обозначающие ситуацию, когда два объекта находятся рядом, не указывая, который из них находится слева, но нет слов вроде bebove или aneath, которые бы обозначали, что один объект находится над другим, не указывая, какой из них выше (для сравнения: в русском языке есть слова «рядом» и «около», но нет слов «внерху» или «ввизу». – Прим. пер.). Наше невнимание к отношению между левым и правым резко контрастирует с нашей повышенной чувствительностью к отношению между верхом и низом и между передом и задом. Вероятно, в человеческом мышлении не заложен ярлык третьего измерения системы отсчета, связанной с объектом. Когда мы видим руку, мозг может выровнять ось «запястье – кончик пальца» с осью «вверх – вниз», а ось «тыльная сторона – ладонь» с осью «вперед – назад», однако направление оси «мизинец – большой палец» останется незадействованным. Допустим, мозг назовет эту ось «в направлении большого пальца», и тогда левая и правая рука станут для мышления синонимами. Наши сложности, связанные с различением понятий «слева» и «справа», нуждаются в объяснении, потому что любой специалист по геометрии сказал бы, что они ничем не отличаются от «вверху», «внизу», «впереди» и «позади».
Объяснение заключается в том, что наша путаница с обратными изображениями – нормальное явление для двусторонне-симметричных животных. Идеально симметричное существо логически неспособно отличить «лево» от «права» (если только это не существо, способное реагировать на распад кобальта-60!). У естественного отбора не было особых причин конструировать животных асимметрично, чтобы они могли мысленно представлять формы отличными от их отражений. На самом деле, логичнее было бы сказать наоборот: у естественного отбора были все причины конструировать животных симметричными, чтобы они мысленно не представляли формы отличными от их отражений. В среднего размера среде обитания, где животные проводят свои дни (больше, чему субатомные частицы и органические молекулы, но меньше, чем атмосферный фронт), лево и право не играют особой роли. У объектов реального мира, начиная от одуванчика и заканчивая горой, верхняя часть заметно отличается от нижней; у большинства движущихся объектов передняя часть значительно отличается от задней. Однако ни у одного природного объекта левая часть не отличается от правой настолько заметно, чтобы это сказывалось на зеркальном изображении. Если сейчас хищник зашел справа, в следующий раз он может зайти слева. Все, что было извлечено из опыта первой встречи, должно распространяться и на зеркальное изображение. Иными словами можно сказать так: если вы сделали диапозитив пейзажа и кто-то перевернет его вверх ногами, это сразу будет заметно, но если кто-то перевернет его задом наперед, вы даже не заметите изменения, если только ваш пейзаж не будет содержать какой-нибудь объект, сделанный человеком – например, автомобиль или надпись[294].
И здесь мы опять возвращаемся к буквам и к мысленному вращению. Для ряда человеческих занятий – например, вождения и письма – различение левой и правой стороны играют значительную роль, поэтому мы учимся различать их. Как? Мозг и тело человека слегка асимметричны. Одна рука всегда доминирует из-за асимметрии мозга, и это различие ощутимо. (Раньше слово «справа» определялось в словарях через ссылку на сторону тела с более сильной рукой, поскольку было принято считать, что все люди – правши. Более современные словари – вероятно, из уважения к угнетенному меньшинству – используют другой асимметричный объект, Землю: «справа» означает в той стороне, где располагается восток, если вы стоите лицом на север.) Привычный способ отличить предмет от его зеркального изображения – повернуть его так, чтобы он располагался лицом вверх и вперед, и посмотреть, к какой стороне тела – с ведущей рукой или с не-ведущей рукой – обращена его наиболее выдающаяся часть. Тело человека используется как асимметричная система координат, которая делает логически возможным различение между фигурой и ее зеркальным изображением. Так вот, испытуемые Купера и Шепарда, по-видимому, делали то же самое – если не считать, что они поворачивали фигуру не в реальности, а в мыслях. Чтобы определить, видят ли они нормальную букву «R» или «R» в зеркальном отражении, они вращали мысленный образ ее формы до тех пор, пока она не располагалась вертикально, а потом определяли, находится ли полукруг с правой или с левой стороны воображаемой буквы.
Итак, Купер и Шепард показали, что разум способен поворачивать предметы, а также продемонстрировали, что один из аспектов присущей предмету формы – ее направленность – не заложен в трехмерной геонной модели. И все же, несмотря на всю свою притягательность, направленность является столь своеобразной характеристикой Вселенной, что по экспериментам с мысленным вращением мы не можем делать кардинальных выводов о распознавании формы вообще. Вполне может оказаться, что мышление накладывает на предметы трехмерную систему координат (для нахождения соответствий геонам), детализированную вплоть до того, в какую сторону должна быть направлена стрелка на горизонтальной оси. Как говорится, проблема требует дальнейшего исследования.
* * *
За дальнейшие исследования взялись мы с психологом Майклом Тарром. Мы создали собственный маленький мир выдуманных фигур и деспотически строго следили за тем, чтобы о них никто не узнал заранее, поскольку нашей целью была объективная проверка правильности трех обсуждаемых гипотез.
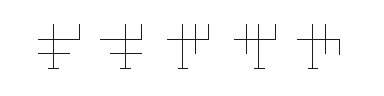
Фигуры были достаточно похожи друг на друга, чтобы испытуемые не могли использовать в качестве подсказки ту или иную характерную закорючку. Ни одна фигура не являлась зеркальным изображением другой, чтобы людей не сбили с пути особенности зазеркального мира. У каждой фигуры было небольшое, но легко различимое основание, чтобы у испытуемых не возникало проблемы с нахождением верха и низа. Мы давали каждому человеку запомнить три фигуры, а потом просили его опознать их, нажимая на одну из трех кнопок, когда та или иная фигура появится на дисплее компьютера. Каждая фигура появлялась несколько раз в разных положениях. Например, фигура № 3 могла появиться около сотни раз в положении верхней частью на четыре часа и около сотни раз – в положении верхней частью на семь часов. (Все фигуры и их положения появлялись в произвольном порядке.) Таким образом, у людей была возможность запомнить, как каждая фигура выглядит в нескольких видах. Наконец, мы предложили им новую серию тестов, в которых каждая фигура появлялась в двадцати четырех положениях с равными смещениями между положениями (опять же в произвольном порядке). Мы хотели посмотреть, как люди справятся со старыми фигурами в новых положениях. Время каждого нажатия кнопки было измерено с точностью до одной тысячной секунды.
Если верить теории множества видов, люди должны были создавать отдельный файл в памяти для каждого положения, в котором объект появлялся на экране. Например, они должны были создать файл, изображающий, как фигура № 3 выглядит лежа на левом боку (а именно в таком виде они ее запоминали), а потом второй, изображающий, как она выглядит в положении на четыре часа, и третий – для положения на семь часов. Люди должны были вскоре научиться очень быстро распознавать фигуру № 3 во всех этих положениях. Когда мы затем неожиданно представили их вниманию те же фигуры, но в других положениях, они должны были думать немного дольше, потому что им необходимо было бы ввести новый вид в ряд уже знакомых видов, чтобы привести его в соответствие с остальными. На каждое из новых положений должно было потребоваться дополнительное время.
Если верить теории мысленного вращения, люди должны были быстро распознавать фигуру в вертикальном положении и все медленнее и медленнее – по мере ее отклонения от этого положения. Фигура, перевернутая вверх ногами, должна была занять больше всего времени, потому что для ее распознавания требуется поворот на все 180°; фигура в положении на четыре часа потребовала бы немного меньше времени, потому что для нее нужен поворот только в 120°, и т. д.
Если верить теории геонов, положение вообще не должно было иметь значения. Люди запомнили бы объекты, мысленно создавая описание каждой линии и пересечения в системе координат, привязанной к объекту. А когда на экране начали мелькать задания теста, для них было бы безразлично, как расположена фигура: на боку, с наклоном или вверх ногами. Наложение системы координат должно было быть быстрым и безошибочным, а описание фигуры относительно системы координат каждый раз совпадало бы с хранящейся в памяти моделью.
Конверт, пожалуйста. И победителем становится…
Все вышеперечисленное. Люди определенно хранят в памяти несколько видов каждой фигуры: когда фигура появлялась в одном из своих привычных положений, люди очень быстро ее идентифицировали.
Люди определенно вращают фигуры в уме. Когда фигура появлялась в новом, незнакомом положении, чем дальше ее нужно было поворачивать, чтобы совместить с наиболее близким к ней из знакомых видов, тем больше времени занимало у людей распознавание.
Наконец, – по крайней мере, для некоторых фигур – люди используют систему координат, привязанную к объекту, как в теории геонов. Мы с Тарром провели еще один вариант этого эксперимента, в котором использовались фигуры с более простой геометрией:
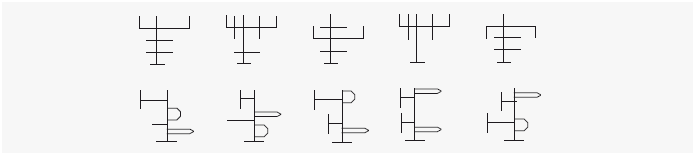
Фигуры были симметричны или почти симметричны, либо всегда имели одинаковые украшения с обеих сторон – так, чтобы людям никогда не приходилось описывать, как располагаются эти элементы по вертикальной или по горизонтальной оси в одной и той же системе координат. Что касается этих фигур, люди одинаково быстро узнавали их в любом положении, в положении вверх ногами – ничуть не медленнее, чем в правильном положении.
Итак, люди используют все эти приемы. Если левая и правая стороны фигуры не слишком различаются, они хранят ее в форме трехмерной геонной модели с центром в системе координат самого объекта. Если фигура более сложная, они хранят копию того, как она выглядит в каждом из положений, в котором они ее видели. Если фигура появляется в незнакомом положении, они мысленно вращают ее, совмещая с ближайшим из знакомых положений. Наверное, удивляться здесь нечему. Распознавание формы – это такая сложная задача, что единый универсальный алгоритм может просто не подходить для любой фигуры в любых условиях наблюдения.
Позвольте закончить эту историю самым радостным моментом для меня как для автора эксперимента. Вероятно, вы с недоверием восприняли эту идею мысленного вращения. Ведь все, что мы выяснили, – это что наклонные фигуры распознаются более медленно. Я поспешил сделать вывод, что люди вращают мысленный образ, но, может быть, наклонные формы просто сложнее анализировать по другим причинам? Есть ли доказательства того, что люди на самом деле осуществляют имитацию физического вращения в реальном времени, градус за градусом? Проявляются ли в их поведении хоть какие-то намеки на геометрию вращения, которые могли бы убедить нас, что они прокручивают в голове такое кино?
Мы с Тарром обнаружили кое-что, что нас поразило. Мы провели еще один эксперимент, в ходе которого протестировали людей на тех фигурах, которые они изучили, и на их зеркальных изображениях в разных положениях:
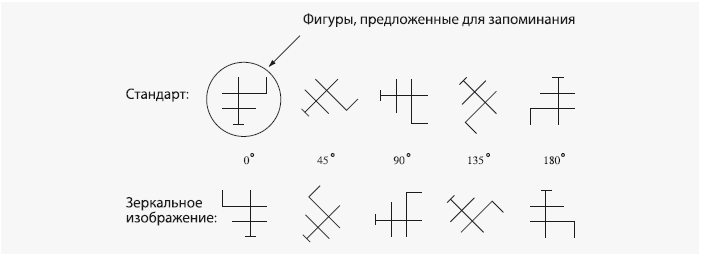
Это не был тест на распознавание зеркальных изображений, как в экспериментах Купера и Шепарда; людям сказали, что обе версии нужно рассматривать одинаково – точно так же, как мы используем одно и то же название для левой и для правой перчатки. Конечно, это естественная тенденция людей. Тем не менее наши испытуемые почему-то все равно воспринимали их иначе. Имея дело со стандартными версиями (верхний ряд), люди изучали их дольше, когда фигура была наклонена больше: каждая последующая картинка в верхнем ряду занимала у них немного больше времени, чем предыдущая. Однако когда речь шла о зеркальных версиях (нижний ряд), наклон не имел значения: на все положения затрачивалось примерно одинаковое время. Казалось, что люди осуществляют мысленное вращение стандартных фигур, но не делают этого с их зеркальными изображениями. Мы с Тарром были вынуждены написать статью, в которой уверяли читателя, что люди используют другую стратегию для распознавания зеркальных изображений. (В психологии объяснять непонятные данные с помощью «стратегий» – последнее средство, к которому прибегают, если не имеют понятия, что с ними делать.) Однако как раз в тот момент, когда мы уже готовили последний вариант рукописи к публикации, нас осенило.
Мы вспомнили теорему геометрии движения: двухмерную форму всегда можно совместить с ее зеркальным отображением путем вращения не более чем на 180°, при условии, что вращение происходит в третьем измерении вокруг оптимальной оси. Теоретически любую из наших зеркальных фигур можно было развернуть в глубину таким образом, чтобы она совпала со стандартной вертикальной формой, и на каждый такой разворот потребовалось бы одинаковое количество времени. Зеркальное изображение с наклоном в 0° просто развернулось бы вокруг вертикальной оси, как вращающаяся дверь. Перевернутая на 180° фигура могла бы повернуться, как цыпленок на вертеле. Фигура, лежащая на боку, могла бы развернуться вокруг диагональной оси примерно так: посмотрите на тыльную сторону правой руки, держа ее пальцами вверх; теперь посмотрите на свою ладонь, повернув ее пальцами влево. Для разворота других смещенных фигур могут служить различные наклонные оси; в каждом из этих случаев вращение составит ровно 180°. Это предположение идеально подошло бы для объяснения наших данных: возможно, люди мысленно вращали все фигуры, но действовали при этом оптимально – стандартные фигуры поворачивали по кругу в плоскости изображения, а зеркальные изображения поворачивали в глубину, выбирая наиболее подходящую ось для поворота.
Мы с трудом могли в это поверить. Неужели люди способны выбрать оптимальную ось для разворота, даже не зная, что за фигуру они распознают? Мы знали, что с математической точки зрения это возможно: найдя всего три выдающихся неколлинеарных точки на каждом из двух видов фигуры, можно вычислить ось вращения, которая позволит совместить один вид с другим. Но действительно ли люди способны произвести это вычисление? Убедиться в этом нам помогла компьютерная анимация. Роджер Шепард однажды показал, что если люди видят фигуру попеременно то в вертикальном, то в наклонном положении, им кажется, что она качается вперед и назад. Поэтому мы продемонстрировали самим себе стандартную вертикальную фигуру, чередующуюся с одним из ее зеркальных изображений с интервалом в секунду. Впечатление, что фигура переворачивается, было таким очевидным, что мы даже не взяли на себя труд искать добровольцев для эксперимента, чтобы подтвердить это. Когда фигура чередовалась с вертикальным отражением, казалось, что она поворачивается на шарнире, как активатор в стиральной машине. Когда она чередовалась с перевернутым отражением, казалось, что она делает обратное сальто. Когда она чередовалась с повернутым на бок отражением, казалось, что она раскачивается туда-сюда на диагональной оси, и так далее. Мозг каждый раз находит оптимальную ось. Участники нашего эксперимента оказались умнее нас.
Решающий аргумент был представлен в диссертации Тарра. Он воспроизвел наши эксперименты, используя трехмерные формы и их зеркальные изображения, которые вращались в плоскости изображения (см. рисунок внизу) и в глубину:
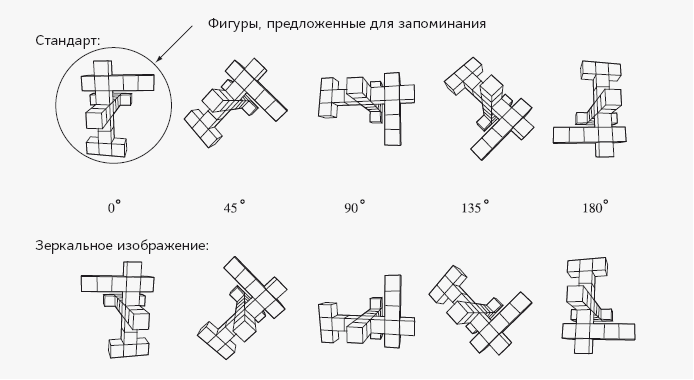
Результаты были такими же, как для двухмерных фигур, за исключением того, как люди поступали с зеркальными изображениями. Точно также, как смещенная двухмерная фигура может быть приведена к стандартному положению путем вращения в двухмерной плоскости изображения, а ее зеркальное изображение можно привести к стандартному положению путем переворота на 180° в третьем измерении, смещенную трехмерную фигуру (верхний ряд) можно привести к стандартному положению в трехмерном пространстве, а ее зеркальное изображение (нижний ряд) можно привести к стандарту путем переворота на 180° в четвертом измерении. (В рассказе Г. Дж. Уэллса «История Платтнера» главный герой в результате взрыва оказывается в четырехмерном пространстве. Когда он возвращается, то обнаруживает, что сердце у него с правой стороны и что он пишет левой рукой справа налево.) Единственное различие состоит в том, что простые смертные, очевидно, не могут мысленно вращать фигуру в четвертом измерении, поскольку наше ментальное пространство ограничено тремя измерениями. Во всех версиях наблюдается зависимость от наклона, в отличие от того, что мы выявили в ходе эксперимента с двухмерными фигурами, где у зеркальных отображений ее не наблюдалось. Получилось вот что. Тонкое различие между двух- и трехмерными объектами решило исход дела: мозг вращает фигуры вокруг оптимальной оси в трех измерениях, но не более чем в трех. Одним из приемов, стоящих за нашей способностью распознавать предметы, определенно является мысленное вращение[295].
Мысленное вращение – еще один талант нашей весьма одаренной зрительной системы, причем талант с особой изюминкой. Зрительная система не просто анализирует очертания предметов, поступающие из внешнего мира, но и создает собственные очертания в форме призрачных движущихся образов. И это подводит нас к последнему вопросу в теме психологии зрения.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОК